
The State of Spring on Kubernetes
The 2021 State of Spring report has two main data points:
- Spring is the defacto standard for running cloud-native applications in Java.
- Kubernetes is the defacto standard for running containerized workloads in production.

This begs the question - what kind of best practices and considerations should be taken into account when running Spring on Kubernetes?
In this article, I shall highlight some of the learnings and best practices that have formed around running Spring (and more broadly Java) applications on Kubernetes. This document is not entirely based on first-hand experiences, but more a collection of conclusions and best practices I identified in the community and when working with customers. These are also based on my own personal observations and are not endorsed by my employer.
You might think that in order to run a Spring Boot app in Kubernetes, all you have to do is quickly jot down a Dockerfile and be done with it.
As Kramer learned the hard way, it’s never that easy:
Kubernetes. pic.twitter.com/SEt6wVklmq
— den (@DennisCode) August 18, 2022
You may consider a developer platform such as Tanzu Application Platform to offload some of these infrastructure decisions to a platform, but even with a PaaS there are architecture and topology decisions to be made. Besides, if you build it - you own it. It’s probably a good idea to know what you’re owning.
Build & Run
There two separate yet equally important aspects of running a production-ready Spring application in Kubernetes:
- Building the OCI image (a.k.a., the “Docker” image)
- Running the OCI image on Kubernetes
Each step has its own gotchas and intricacies. Let’s review these in details.
Building the image
At first, this sounds fairly simple. Just Google some sample Dockerfile for a Java application and use it as reference.
In reality, there are many important decisions that will impact your target image and how it behaves with regards to the Java Virtual Machine it is running.
Choose a Linux distribution
There are so many Linux distros out there that it gets hard to keep up. Should you go with Ubuntu? RedHat Enterprise Linux? Debian? Suse? Alpine? Distroless? Which one makes more sense for your JDK-based OCI image?
For containerized JDK workloads, the question should actually be more generalized. It should be focused on which Linux kernel you are going to base your container on.
There’s a good reason why you can run a Red Hat Enterprise Linux container on an Ubuntu VM, or a Debian Linux container on a PhotonOS VM. The important pieces for a Linux-based container are:
- libc, which is at the core of OCI images. This is practically the same programming interface, regardless of the Linux distribution you plan to use.
- The Linux kernel Application Binary Interface (ABI), which guarantees backwards compatibility between different Linux kernel versions.
Based on this information, it sounds like you shouldn’t really care which Linux distribution you’ll use. However, the devil is in the details.
There are two popular implementations for the libc interface:
- GNU libc: This is the standard library that you probably use every day. It is used by Ubuntu, Debian, CentOS, RHEL, SUSE and more. Its downside is that it is a fairly large and heavy codebase (in container terms).
- Musl libc: This is a newer implementation of the library. Used by Alpine Linux, it is much smaller in size compared to GNU libc and is meant to be lightweight, fast and simple. However, there are caveats. Musl libc actually has functional differences compared to GNU libc - things like regular expressions, EOF and multithreading could behave differently based on the implementation. [See this detailed comparison]
It sounds like the implementation details are less important when you work against an interface, but that’s not the case for the Java Virtual Machine. Until fairly recent versions, the JVM relied on features that were only available in GNU libc, and modifications had to be made to support the Musl implementation.
Starting with Java 16, both implementations are supported. Since you’ll probably want to stick to Java long-term support releases, in practice this means that you should only rely on Alpine-based distros starting with Java 17 and later.
For best compatibility, use a GNU-based libc Linux implementation. At VMware Tanzu, we use Ubuntu extensively for Spring-based images and find it to be an excellent choice, but other solutions should work just as well: RHEL, Debian, PhotonOS, SUSE, CentOS etc.
Choose a JDK distribution
If you ever installed SDKman on your machine, you know there are a plethora of JDK distros out there:
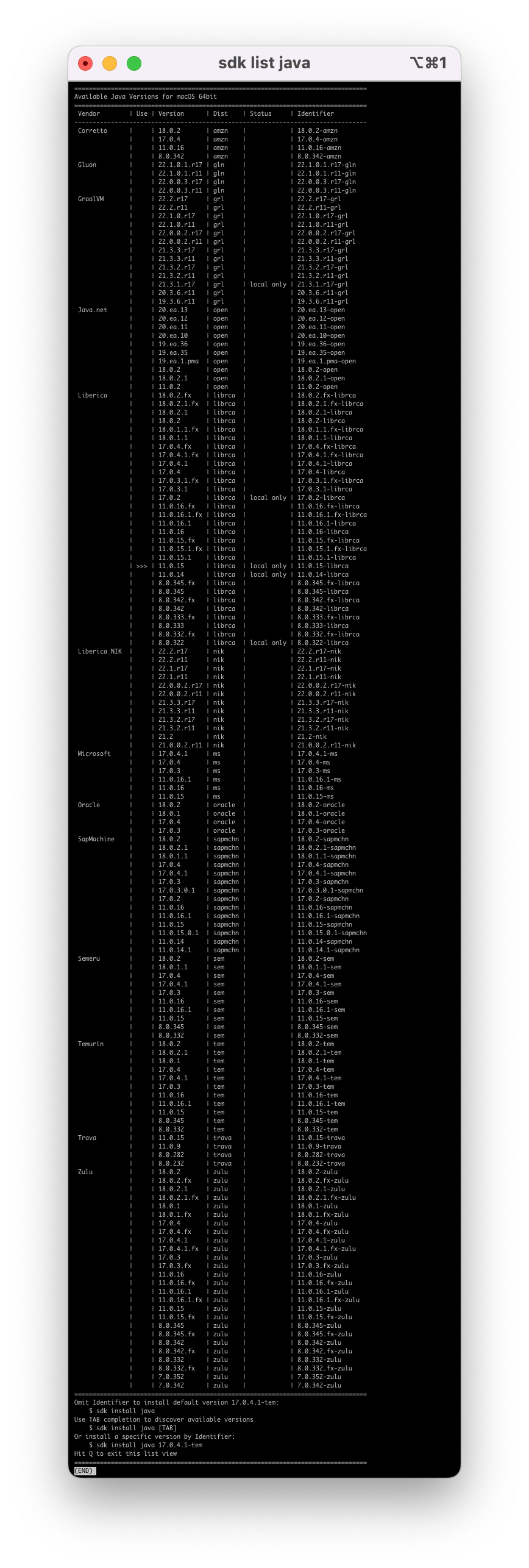
If that’s not enough, there is also a long list of JDK base images to choose from in Docker Hub. Merely searching for Java returns a single official image with the label DEPRECATED; use openjdk or other jdk implementations instead.
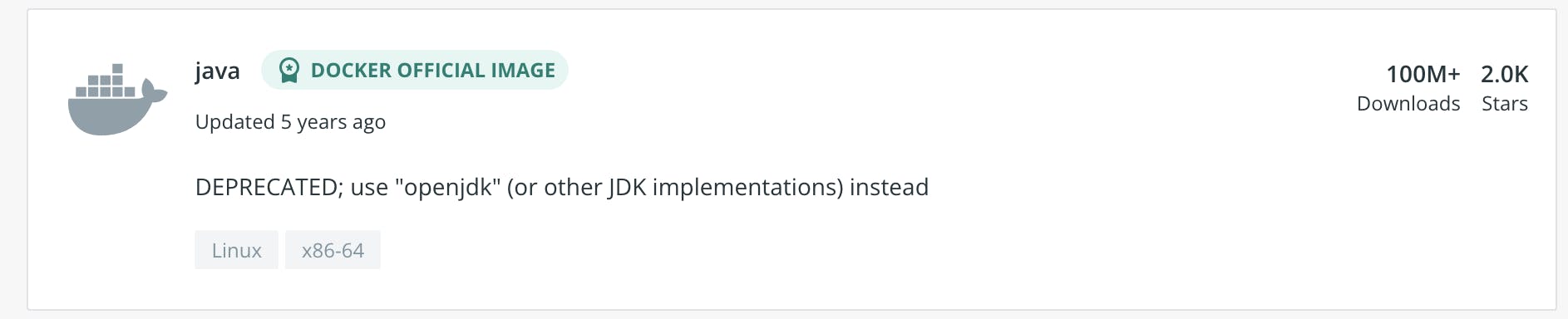
A search for openjdk returns over 6,500 results. The first two results are “Docker Official images”, one for OpenJDK with over a billion downloads, and one for Eclipse Temurin with over 10 million downloads:
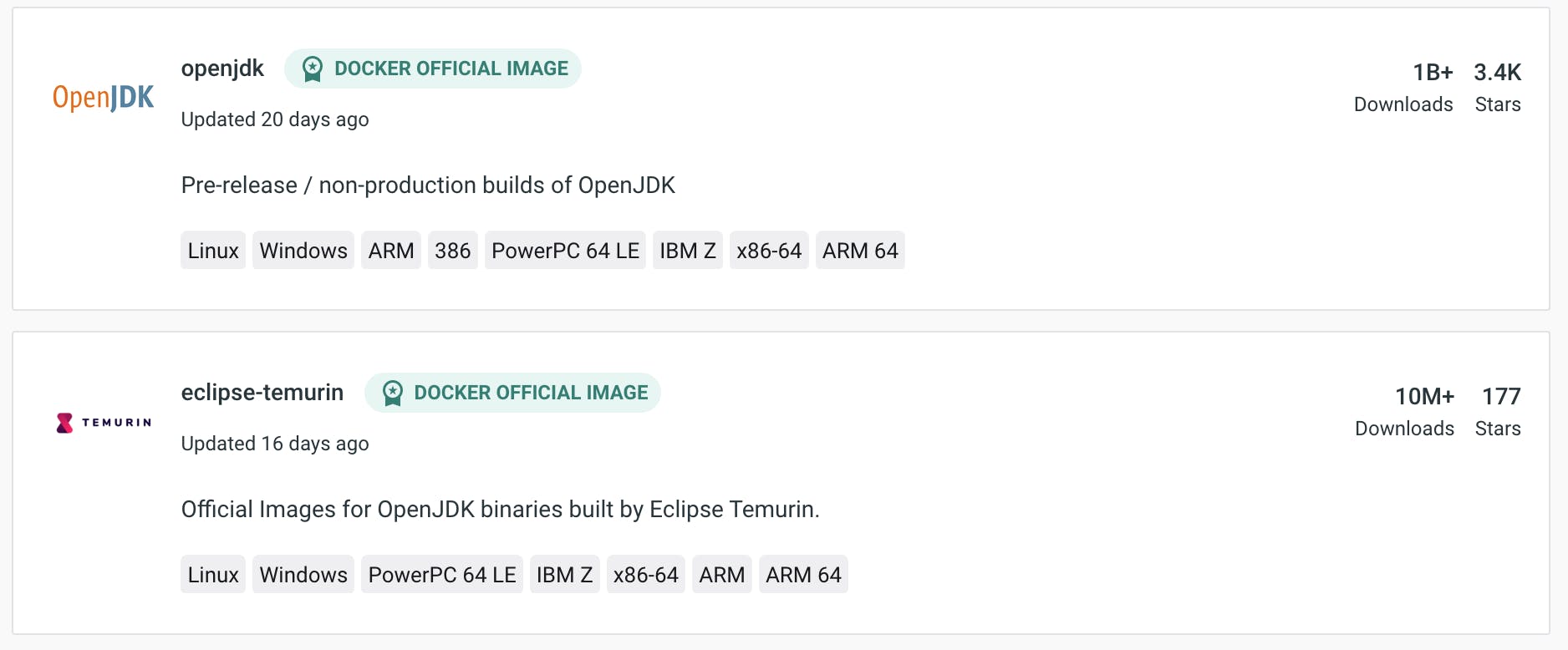
These sounds like good choices. Just be aware that “official” doesn’t necessarily mean what you think it means. It just means that the build itself is done by Docker - and sometimes this can cause more harm than good.
Matt Raible has a very good article on the different distros available out there, although some distribution names have changed since its publishing at 2019.
For OCI images, there are three variants that you should consider:
- Oracle JDK - requires license for production use. This is the “official” JDK.
- OpenJDK, built and maintained by Oracle, and free. Oracle’s OpenJDK doesn’t offer support for Java 8 anymore.
- Adoptium (the rebranded AdoptOpenJDK distribution) is built and maintained by the community. It is compatible with Oracle’s version while having more “friendly” licensing terms. Vendors such as Bellsoft, IBM, Amazon and others offer JDK distributions based on AdoptOpenJDK.
The decision on which JDK to use has many factors, so it’s hard to make a single recommendation.
- If your company already has an Oracle license, use their JDK base images.
- If you are running on a single public cloud provider, consider using that cloud provider’s JDK release, such as Amazon Corretto or Microsoft’s build of OpenJDK.
- If you are looking for a fair and production-ready distribution that is community-driven and can run anywhere, use the Adoptium-provided base images, or one of the various flavors based off of it with commercial support, such as Azul or Bellsoft Liberica. VMware Tanzu (the business unit that the Spring team is a part of) uses Bellsoft Liberia in products such as Tanzu Build Service and Tanzu Application Platform.
Use the Adoption base images such as
eclipse-temurin:17-jre-jammy, or a supported flavor of the builds. If you run on a single public cloud, consider using that cloud provider’s base image. If you have a license for the Oracle JDK, use it.
Choose a JDK version
Oh, this one’s easy. Use the latest LTS version that you can. At the time of this writing, the latest LTS version is Java 17.
LTS stands for Long-Term Support, and in general the industry tries to stick to those releases unless there are very important reasons to move to other versions. Non-LTS versions are released every 6 months and are supported for fairly short cycles, while LTS versions are being supported for many years (5+ based on the distribution).
Starting with Spring Framework 6.0, the minimum supported version will be JDK 17.
Support is just one aspect of the selected version. Each version also introduces new features, but more importantly - better performance, better security and improvements to the garbage collector.
Here’s the startup time for the famous Spring Boot Petclinic application while running in a Java 11-based container based on Bellsoft Liberica on a 4-cores machine running macOS:
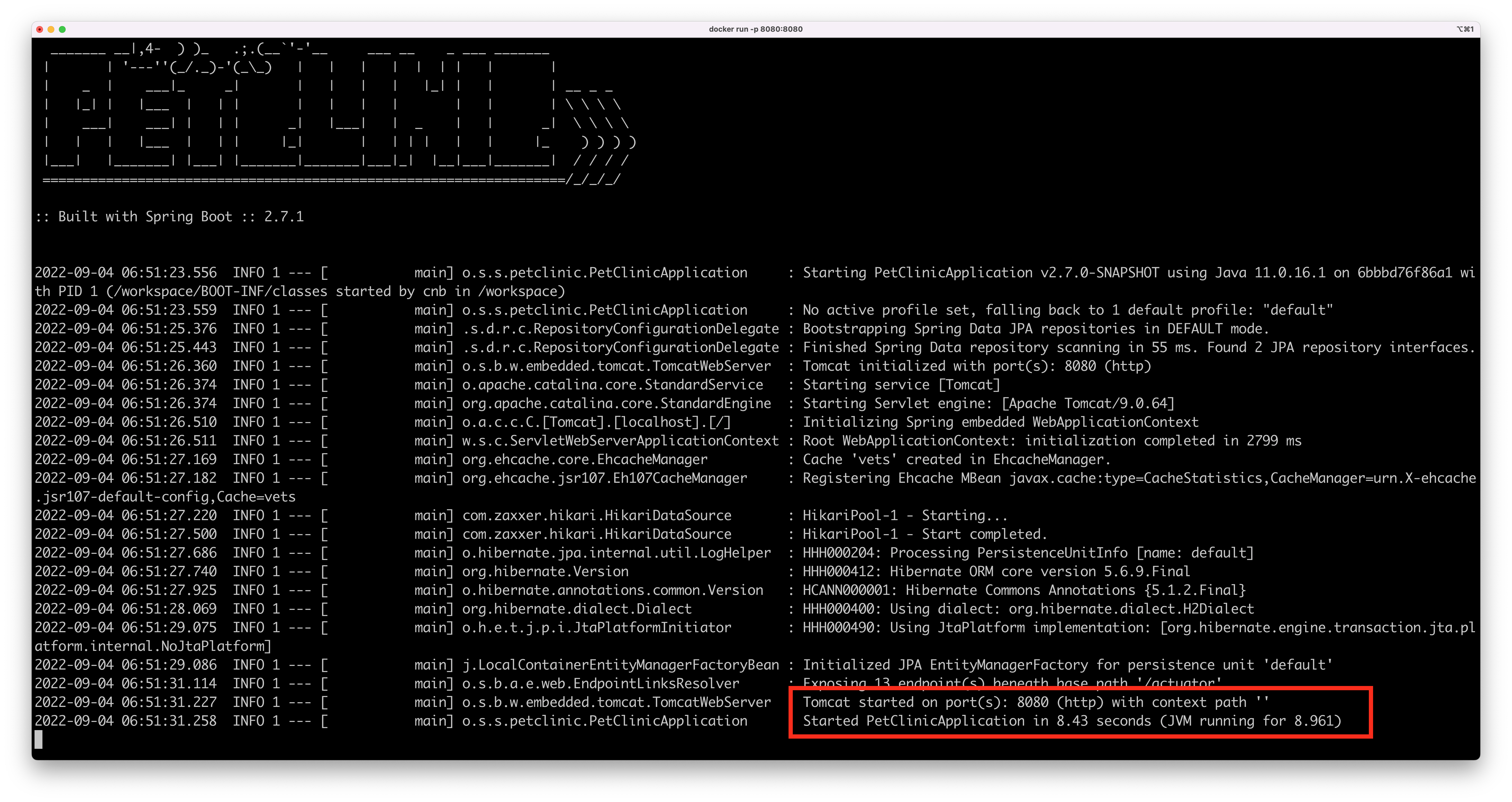
And here’s the same application running on a Java 17 container, also based on Bellsoft Liberica, on the same 4-cores machine running macOS:
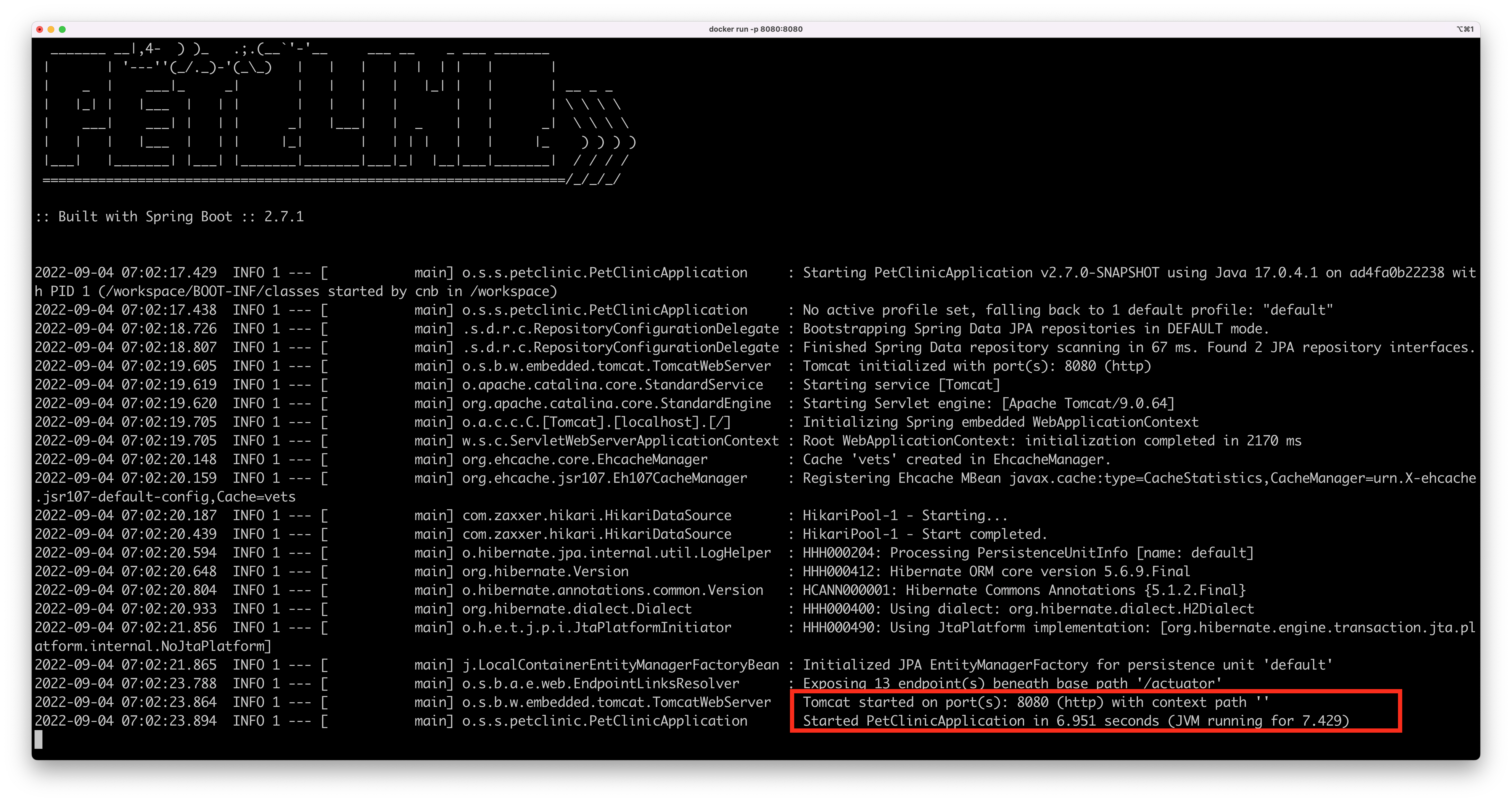
That’s a 1.5 seconds difference just by upgrading your JVM. It may not sound like a lot, but in a Kubernetes environment where pods go up and down at any given moment, that’s a lot.
If you can’t use Java 17 due to compatibility issues, use Java 11 - the previous LTS version.
Java 8
Now, I know what some of you are thinking right about now: “What are you talking about? we’re still stuck with Java 8 and we can’t upgrade anytime soon”. If that’s you - you’re not alone. According to a recent survey by JRebel, more than a third of Java developers are still using Java 8 in production, and that’s not going to change in the near future. If you still have to use Java 8, that’s ok (🫤), but start planning your strategy to upgrade. Also - there are several important caveats to consider:
In containerized environments, Use Java 8 update 191 or later. Older versions of Java 8 are not compatible with containerized environments, and the JVM mistakenly reports the host’s CPU and memory instead of the container’s. Here’s an example for running an application with Java 8 update 131 on a Linux VM with 4 CPUs and 16 GB of RAM:
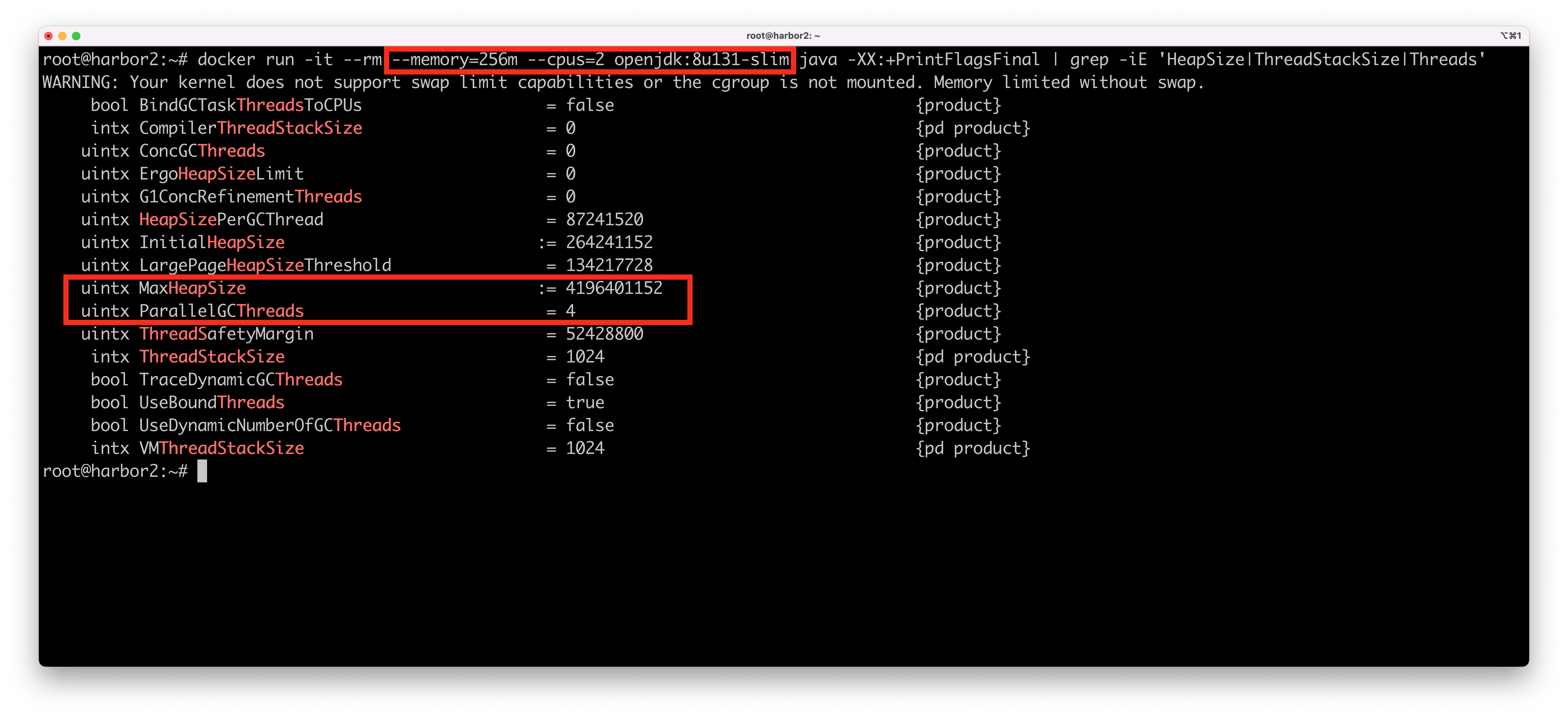
As you can see, in Java 8 update 131 - the container uses all available CPUs on the host although I asked the container to limit the container to just 2 CPUs. Also - the available memory is set to 4 GB although I asked for a container with just 256 MB (the max heap size is always calculated as a portion of machine’s available memory, as a default that it is 1/4 of the host’s memory). This can cause extremely unpredictable results, especially since many thread pools such as those used by Tomcat and thread pools use the number of available processors (Runtime.getAvailableProcessors()) to calculate the size of the pool, which translates to larger native memory usage, which eats more of the total available memory, which in turn, again, can cause havoc.
If that’s not enough, the JVM also chooses the garbage collector based on available CPU and Memory. You will get different garbage collectors based on different CPU and memory configurations.
So, if you have to use Java 8 - use a recent version, update 191 or later. You’ll also get a ton of security patches which are critical for production environments.
Here’s the same docker run command on the same Linux VM, but with Java 8 update 292:
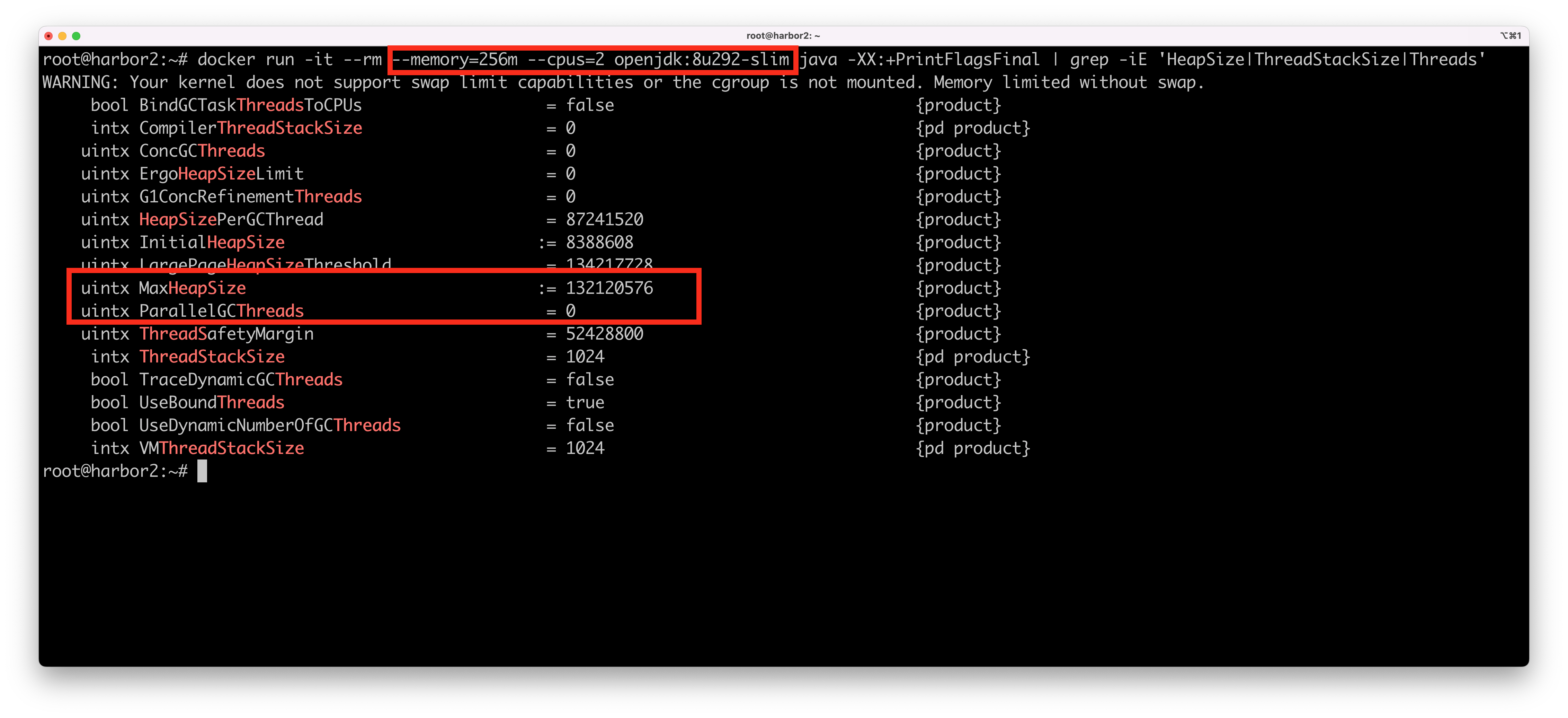
This time, our JVM reports a max heap size of 132 MB and no parallel garbage collection threads. Also - all thread pool using the Runtime.getAvailableProcessors() command will get the correct number of processors, and therefore will generate reasonable pools with reasonable native memory sizes.
An important note that goes without saying: there are always refinements and enhancements, and bugs are always a possibility, so use the latest patch version based on your target JDK version. Just recently, a patch was made to support cgroups v2 because the first time the feature got implemented, only cgroups v1 was available. Adding support for cgroups v2 with Java 8 is still ongoing development at the time of this writing.
Use Java 17 LTS. If you can’t use Java 17, use Java 11 LTS. If you can’t use Java 11, use Java 8 update 191 or later. Do not use earlier versions of Java in a containerized environment such as Kubernetes.
Writing a Dockerfile
If you’ll Google “Spring Boot Dockerfile”, you might run into this article. In it, the first section lists the following example:
This Dockerfile will work just fine, but I would advise you to avoid it. The above Dockerfile places the Spring Boot “fat jar” into a single OCI layer. This uber jar can easily reach 150 MB or more. What does this mean in practice? It means that for every new build, even for the simplest code change in our application:
- A new 150 MB layer (read: tarball) will be created
- The layer will be uploaded to your OCI registry
- When Kubernetes pulls the latest image to the node that runs the container, the entire 150 MB layer will need to be pulled.
This will happen on every single code change and rebuild of the image. In reality, only a very small sliver of compiled code has changed. Dockerfile treats each new line as a new layer, so it would make a lot more sense to put the third party dependencies in their own layer and have our custom code in its own layer. But how should you layer your Spring Boot image? Which app stack should be treated as its own layer?
Luckily, Spring Boot has you covered. Let’s take the same Petclinic application, build it, and ask Spring to list what it thinks are the correct layers that are suitable for an OCI image. We can use a special execution mode called layertools:
|
|
As you can see, instead of running the Spring Boot application, passing the argument -Djarmode=layertools list to the java command will simply list the layers that make sense for Spring Boot application. In our case, these are:
- Dependencies - the Spring Boot and other frameworks’ release-based dependencies. These only change when we upgrade a Spring Boot version or the third party framework version.
- Spring Boot Loader - this is the code that loads our Spring Boot app into the JVM to manage the bean lifecycle, among other things. This also rarely changes.
- Snapshot Dependencies - these dependencies are changing much more often. It’s possible that on each new build it would require us to pull latest snapshot. As a result, this layer is the closest to our application code.
- Application - This is our application code from
src/main/java(in the case of maven).
So, Spring Boot helps us with hints on how best to layer our application. But wouldn’t it be better if it could actually prepare the layers for us? Well, it can do exactly that:
|
|
Let’s see the contents of the dependencies folder for example:
|
|
And here is our application’s compiled code:
As you can see - this process takes our uber jar and explodes it to make it suitable for a layered OCI image. If you’ve been around long enough like me and have flashbacks to exploded EAR files, you’re not alone. Technology has a tendency to repeat itself.
We can now incorporate the exploded directories into our Dockerfile:
|
|
Let’s see our OCI image in action:
|
|
Our exploded Spring Boot app started in just under 6 seconds, which is quite impressive! Let’s compare it to the original Dockerfile that used the far jar approach:
|
|
Our application is slower by almost 1.5 seconds while running on the same machine and the same Docker engine. Add to that the overhead of pulling and storing an entire 150mb+ layer on every single change from a remote registry, and you’ll quickly understand the benefits of this approach.
Customizing the layers
You might have your own set of release dependencies that are not part of the dependencies provided by Spring. For example, your company might be using an internal set of dependencies for security, logging and auditing that you need to include in every Spring Boot application. It might make sense to extract such dependencies into their own layer as well since they may change more often than the Spring dependencies. To do it, you can create a custom layers configuration:
|
|
To apply this configuration in your application, point the spring-boot-maven-plugin to the custom layer configuration:
|
|
Don’t forget to change your Dockerfile accordingly:
|
|
Avoid using uber jars in your Dockerfiles. Use Spring’s builtin layertools to explode the jar for more efficient packaging in an OCI image.
Setting bootstrap arguments
In the example above, we ran the Java application with everything as default:
|
|
These defaults may be ok, but they’re probably not. There are too many variables that are taken into consideration by the JVM to decide on things like the heap size, available memory and garbage collection algorithm. Always profile your app before production and apply settings that you feel were validated in production-like environments. At the last section of this article I will include some profiling tips that may help you.
There are many ways to pass arguments to the JVM. In containerized environments, it’s best to use the JAVA_TOOL_OPTIONS environment variable since it’s the safest choice that can be read by the JVM inside a container. No, do not use JAVA_OPTS - this is a shell script convention and the JVM doesn’t honor it.
Some of the more important arguments to pass to the JVM have to do with memory management. You’ll need to take several things under consideration:
- Your JVM memory is (mostly) a combination of the heap memory and the non-heap memory (Stack Memory, Direct Memory etc.).
- Most of your application’s memory will be allocated to the heap. How much memory should you assign to it? It depends!
- How much memory does the container has?
- How many classes are in-memory?
- How many threads are running at the same time (including Thread Pools)?
- How much memory is taken up by the Stack memory?
- Your application may also use a considerable amount of non-heap memory for things like NIO Direct Memory. For example, Kafka and many other socket-based frameworks make use of NIO for better performance. Without setting proper arguments, it might kill your JVM without you realizing what happened (as I learned the hard way…). Profile your application for direct memory by including the JVM arguments
-XX:NativeMemoryTracking=summary-XX:+PrintNMTStatistics. Add the resulting value to the total memory footprint calculations.
At Pivotal (who later became VMware Tanzu), we developed a useful little tool that helped us with these memory calculations. Originally developed for Cloud Foundry, the Java Buildpack Memory Calculator was created to help developers on the platform, who really just wanted to cf push their Spring application and have the platform build the image for them without thinking too much on production optimizations. This tool still exists and provides a great starting point for you to consider when setting memory arguments.
The calculator takes as input the parameters from above like expected Stack memory, expected number of classes, expected number of concurrent threads etc. You still need to profile your app to get some understanding of what these values mean in your use case. The calculator would then output the recommended max heap size based on our research and real-world experience. The algorithm is clearly documented in the github repo.
For example, let’s say my application has 750 classes, my container has 1G of total memory, I expect my stack size to be around 1Mb, and I calculated the total threads used by my application to be around 100 threads, give or take. I’ll run the command as follows:
The memory calculator gave a recommended max heap size of around 670 megabytes, based on the algorithm total memory - (headroom + direct memory + metaspace + reserved code cache + (thread stack * thread count)). To clarify how important the thread pool is to this calculation, let’s imagine our application uses Tomcat and utilizes 200 additional threads for Web requests, bumping the total number of threads to 300. The calculation is now:
Our max heap size is now down to around 470 megabytes.
Notice that the tool always gives a default value for MaxDirectMemorySize of 10M. That’s because there’s really no way of telling the true amount to be used without profiling the application, so it chose some sane default. Remember to check your direct memory usage as mentioned above. It could have a meaningful impact your heap size. Let’s say our application uses Kafka with many concurrent consumers, and therefore requires 64 MB for direct memory. The calculation will now be:
Our heap size is now down to just ~410 megabytes. Perhaps 1 gigabyte for the container is not enough at this point?
As mentioned before, the JVM memory arguments are entirely dependent on the target deployment environment and available container memory. You wouldn’t want to hardcode these values into the Dockerfile, since they keep changing. You have three options here:
- Set the
JAVA_TOOL_OPTIONSenvironment variable as part of your Kubernetes deployment yaml (more on this later). - Calculate the arguments when the container starts, but before running the actual Spring-based application. The next section shows how this is done.
- Use a mixture of options 1 and 2. Set what you can in your deployment manifest, and let the container additional calculate arguments on startup.
Who needs Dockerfiles?
It’s almost 2023. You don’t compile your own Linux kernels anymore, I would hope. Why are you still writing Dockerfiles?
Docker images (well, OCI images, to be exact) are great. They are the golden standard for container packaging that can run anywhere. But Dockerfiles are really just scripts to build these images. It’s been around since the time that OCI images became popular, so they are considered the default. We have other ways to get a working OCI image, and some of options are more focused on the what than on the the how. One of these tools is jib. It’s developed at Google and can integrate with your build tools to automatically create a Java distroless container image for you without the hassle of writing the perfect Dockerfile. But there’s also a standard that can be used for a wider context than just Java images.
Cloud Native Buildpacks
Cloud Native Buildpacks (CNBs) is a specification for how to build OCI images without Dockerfiles, and I would argue it has three major advantages going for it:
- It’s a CNCF project.
- It will proactively patch your base Linux distribution and your OpenJDK (or other middleware runtimes for other languages) on each new build.
- It’s directly integrated into the existing Spring build plugins!
TL;DR, the following will generate a production-ready OCI image for you:
|
|
This command will use many of the things I mentioned above:
- It will create an optimized OCI image based on the layers listed by the
layertoolscommand (unless you’re on Spring Boot 2.3, where it wasn’t the default). - It will run the Java Buildpack Memory Calculator to calculate the correct heap size.
- On container startup, it will set production-ready defaults for
JAVA_TOOL_OPTIONS, taking into account user-provided environment variables and the memory calculation. Here’s the boot logs of a container built bymvn spring-boot:build-image, running on a Mac with Docker Desktop that has resource configuration of 4 CPUs and 4 GB assigned memory. Notice thatJAVA_TOOL_OPTIONSis calculated and set before Spring even boots, based on the available container memory:
|
|
Running the same image in a Linux machine with less resources results in different memory values, as it should:
|
|
Security Patching
Cloud Native Buildpacks also have the added value of proactive security patching, which is an incredible feature to have in production. Every time you execute the plugin, Spring downloads the latest Paketo base builder image:
|
|
The builder image is constantly updated with the latest security patches. Image building is done entirely inside this builder container. Every time a new buildpack is available with the latest security patches, it will be applied to the newest build.
|
|
The resulting image is built from the latest Run base image, which is also constantly patched:
This process continues on every new rebuild. Pull the latest patched Builder, apply the latest patched buildpacks, use the latest patched Run image.
If you want to do this process at scale, you can run these builds directly on Kubernetes using the kpack open source project. With kpack, you will have the ability to retroactively patch the base OS without running full rebuilds, using a process called rebasing. kpack has an Enterprise-ready version called Tanzu Build Service that is more suited for enterprises and locations that have no internet access.
Cloud Native Buildpacks in different Spring Boot versions
There are some differences that you should be aware of regarding the build-image implementation:
-
If you’re still using Spring Boot 2.3 (why?), the resulting image will not use the layered approach as described above. In Spring Boot 2.4 and later, this is the default. In order to gain the benefits of better OCI layering in 2.3, you’ll need to provide the following configuration in your
pom.xml: -
In Spring Boot 2.4 and above, there’s an additional enhancement you get for free: The
build-imageprocess will also remove all thespring-boot-starterjars from the target image. These are really only needed at compilation time and not at runtime, so removing them results in smaller images and in better performance. -
In Spring Boot 2.4 and above, you can configure your own custom registry for the target resulting image. Spring Boot will push the image to the remote registry for you as part of the build process - great for CI pipelines. For example:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22<project> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> <configuration> <image> <name>harbor.mysite.com/apps/spring-petclinic</name> <publish>true</publish> </image> <docker> <publishRegistry> <username>my-username</username> <password>my-password</password> </publishRegistry> </docker> </configuration> </plugin> </plugins> </build> </project> -
Starting in Spring Boot 2.5 and later - you can also customize the buildpack that is used to create the resulting image. The Spring Boot plugin uses the Paketo Java buildpack by default. With this new feature, you can use buildpacks from other vendors such as those provided by Google or VMware Tanzu, or even write your own. To reference a different set of buildpacks, use the following configuration:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18<project> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> <configuration> <image> <buildpacks> <buildpack>file:///path/to/example-buildpack.tgz</buildpack> <buildpack>urn:cnb:builder:paketo-buildpacks/java</buildpack> </buildpacks> </image> </configuration> </plugin> </plugins> </build> </project> -
In Spring Boot 2.5 and later, you can create additional image tags for the resulting image, to support better image management that is more suited to your organization. For more information, check out the plugin documentation parameters.
Use Cloud-Native Buildpacks if you can. You will get security patches, simplified workflow, and production-ready defaults.
Running the image
Finally, we have a working OCI image that we can use to run on Kubernetes.
But how do we run this thing?
There are many factors that need to go into consideration when running our image in Kubernetes. Let’s review them one by one.
12 Factor apps
The concept of developing 12 factor apps is still as relevant as ever. Even if some factors seem obvious when running in containers and on Kubernetes, it’s still good to have this north star. Things like dev/prod parity, scaling out via the process model (more containers!), disposability, outputting logs to the standard output, all fit perfectly into the Kubernetes model. There are those who advocate that in this day and age, we need a few more of these factors. Although all of these factors are important, when it comes to Kubernetes there is one thing to consider above all else, so much so that it is sometimes referred to as the “1-Factor app”:
Can it be restarted gracefully?
If it can, then you can let Kubernetes do a lot of things behind the scenes even if your application is not written perfectly according to all the best practices.
Liveness and readiness probes
To make sure your Spring application runs well on Kubernetes, you need understand how Kubernetes interacts with your application during various lifecycle phases. This starts with having your Spring application notify the Kubernetes runtime that it is running and ready to accept traffic.
Actuator health endpoint
Spring Boot has has an endpoint that is designed for something like this. Adding spring-boot-starter-actuator to your classpath will allow you to have various production-ready endpoints that report health and metrics about of your application. By default, the health endpoint is always exposed. In earlier versions of Spring Boot the info endpoint was also exposed by default, but this has since been removed. With the actuator starter in your classpath, you can now add the following to your Kubernetes deployment manifest in order to let Kubernetes know when your application is ready to accept traffic and if it is still considered “alive”:
This is a good starting point. We’re telling our application to accept traffic only when the Spring Boot actuator health endpoint returns 200 OK. If during runtime the endpoint returns an error, we also tell Kubernetes to restart our pod. But there are caveats… as always.
-
Do you really want to restart your pod whenever the health endpoint returns an error? The default actuator endpoint usually returns the overall health of your application, including whether connectivity to a database or a message broker is working as expected. If you cannot access your database, restarting your application won’t do much good beyond adding more strain on your (probably overloaded) database when new connection pools are created on each restart, which might actually cause a cascading failure. Perhaps implementing circuit breakers in your application and add alerting in your monitoring system is a better approach. It does make more sense to set readiness probes based on external components to the application, but even then, “it depends”. You might be ok with some Redis cache being inaccessible on startup, but not ok with the main database being inaccessible.
-
It’s considered a best practice to assign a separate port to the actuator endpoints. That is because these endpoints can reveal sensitive metrics and information about your application, so moving these to a different port allows you to easily block access to this information, while keeping the main application port open to an external service or ingress. This is especially true for distributed and multi-tenant environments such as Kubernetes. To set a different management port, set the following property:
1management.server.port=9090However, there’s a catch here - when it comes to readiness and liveness - you want these probes to exist on the main server application port, and not the management port. That is because probing the management port might result in false positives - the management port might be responding to your requests just fine, while the actual application is still trying to start up correctly.
-
Actuator health endpoints are mostly based around HTTP readiness. If your application is a batch application or a streaming application, you need to provide other verifiers to report if it is ready or not (here I come, you can’t hide…).
Luckily, Spring has you covered.
Spring Liveness and Readiness Health Groups
Spring Boot 2.2 introduced the concept of Health Groups, allowing you to group multiple actuator health indicators under a single group. You can then define specific properties for that particular group only. Spring Boot 2.3 took this concept further by creating two health groups out of the box: a readiness group and a liveness group. To have these two groups enabled, the following setting must be enabled:
|
|
To make your life easier, Spring sets this property to true automatically when it detects the application runs in Kubernetes.
With this new setup, you get the full-blown and detailed health information including dependent resources under /actuator/health, and two separate sub-groups: /actuator/health/readiness and /actuator/health/liveness. Based on the reasons explained in item #1 above, Spring Boot by default does not rely on any external state for readiness and liveness, it is only checking the internal application state. Since these are now two separate groups, you can also customize each group with its own set of checks that is suitable for your application. For example, if your application must have database connectivity before it can report it is ready to accept traffic, you can add that check to the list:
|
|
You might even want to write your own custom checks if you have some unique readiness requirements that are not part of the built-in verifiers. For example, imagine that your application relies heavily on a third party SaaS API such as Twilio to be available before the application is ready to accept traffic. Write a custom verifier that checks the API endpoint and add it to the list:
|
|
On the other extreme, if your application is a batch or a streaming application that doesn’t accept web traffic at all, you might want to rely entirely on a specific external service such as a message broker and nothing else:
|
|
So, we now have better control of what exactly does it mean to have our application “ready” and “alive”.
But we are still conflicted with the fact that most actuator endpoints should live on a separate “management port” for security reasons, while we want our readiness and liveness probes to live on the application port. The Spring documentation for version 2.3 has a big yellow warning specifically on this:
If your Actuator endpoints are deployed on a separate management context, be aware that endpoints are then not using the same web infrastructure (port, connection pools, framework components) as the main application. In this case, a probe check could be successful even if the main application does not work properly (for example, it cannot accept new connections).
Luckily, starting with Spring Boot 2.6, there is a good solution for this. You can now set a health group as an additional path to either the main application port or to the management port. For example:
In addition to whatever was configured as the management port and path, this setting will also make the readiness endpoint available on the main (server:) port, under the HTTP path readyz, and make the liveness endpoint available on the main port under the HTTP path livez. To set a health group to the management port instead of the main server port, use management: as the prefix.
Some more liveness and readiness settings
- A container is considered alive or ready if it returns any HTTP response code between 200-399. Kubernetes doesn’t really care what is returned as long as it is not 4xx and 5xx.
- Some additional settings that could be relevant when defining your liveness and readiness probes:
periodSecondstells Kubernetes how often to poll the endpoint.timeoutSecondstells Kubernetes when to timeout the HTTP request (in seconds) and consider it an error that requires the pod to be restarted.initialDelaySecondsindicates how long to wait before probing. This is especially important for Spring Boot applications that might require a long startup time. Profile your application to figure out the preferred values here. Beware of using an unnecessary long value, because your pod will not be available until that time has passed. Also note that theinitialDelaySecondsfor livenessProbe only begins polling after the application is marked asReady.failureThresholddefines how many times a failed response is considered “ok”. You probably don’t want to immediately kill your pod if a temporary network glitch returned a bad gateway once or twice.
Use Spring’s built-in readiness and liveness health probes. Keep the problems on the main application port, and set a separate management port for other actuator endpoints.
Graceful Shutdown
Ok, we took care of the startup lifecycle. But what about shutdown? In Kubernetes, shutdowns are inevitable. Whenever a cluster node is being upgraded, removed or resized, two things happen:
- A process called
cordonprevents Kubernetes from scheduling new pods on the node (it’s status is changed toSchedulingDisabled). - A process called
drainevicts all the pods from the node. - Maintenance on the node can now be performed (delete/upgrade/resize etc.).
Another common use case for shutting down pods is when autoscaling is being utilized, such as when using a Horizontal Pod Autoscaler, or a runtime like Knative that even scales to zero when there is no traffic.
Regardless of the reason for the shutdown, we want to make sure that our application doesn’t get killed abruptly when it is still processing in-flight HTTP requests or while executing queries against our database. If it gets killed too soon, some clients will receive errors and some database transactions might not be updated (or even corrupted, depending on the database).
Configuring graceful shutdown
By default, even in the latest versions of Spring, the Web server associated with the application will be shutdown immediately. Setting a graceful shutdown in Spring used to be quite cumbersome and required some custom solutions. Thankfully, starting with Spring Boot 2.3, graceful shutdown is supported out of the box:
|
|
With this property set, when the container receives a SIGTERM to begin shutdown, Spring will block the associated Web server (Tomcat, Netty etc.) from accepting any new connections before actually shutting down. We now have a time window to handle in-flight requests without receiving new requests.
We now want to wait for all the in-flight requests to complete before exiting the Spring application. For this, we have a timeout property for the shutdown phase, which defaults to 30 seconds. To override this default, change the property as follows:
|
|
It is likely that you only want to set these parameters while running in the context of Kubernetes. Luckily, this is easily doable since Spring automatically adds a profile called kubernetes when it detects the application runs in Kubernetes:
In the example above, the shutdown properties are only applied if the application runs in Kubernetes. Outside of Kubernetes, the server will shutdown immediately. Also, just for fun, we’re changing the application name.
Prevent new requests coming to a pod that shuts down
Kubernetes is a distributed system working in event loops. As such, eventual consistency considerations must be taken into account. One classic example of this is the fact that a pod might begin the shutdown lifecycle, while other Kubernetes resources continue to route traffic to the pod. In order to block new requests from coming in to the pod when the shutdown flow begins, we can configure a preStop phase in our pod lifecycle:
In this simple use case, we’re telling our application to sleep for 10 seconds once the shutdown lifecycle begins. We allow other components this time window to figure out that our pod is no longer in the game. During that time, initially new requests might still come through to the main application running in the container, but eventually new requests should not be routed. You might need to tweak this wait time based on the size of your cluster and configuration. After this preStop phase completes, we are now at a stage where new requests are (hopefully) not being routed to our pod, while existing in-flight requests are being executed within the timeout-per-shutdown-phase window.
Termination grace period
The flow of a shutdown is as follows:
preStopis being executed (in our example we’re basically waiting for 10 seconds for Kubernetes to get its resources in order with our shutdown).- Kubernetes sends a
SIGTERMto our pod. - Our pod receives the signal and begins the shutdown process. For a graceful shutdown this means blocking any new requests from our Web server and waiting for in-flight requests to complete, up to the value of
timeout-per-shutdown-phase.
Here’s the caveat: the value for terminationGracePeriodSeconds defines how long Kubernetes will wait before violently killing your pod with a SIGKILL signal. The default is 30 seconds. But when should we start counting these 30 seconds? The answer is: from the beginning of the preStop phase. In practice, this means that you should set the terminationGracePeriodSeconds to a value higher than the sum of the preStop execution time + timeout-per-shutdown-phase time, otherwise your pod will always get killed abruptly. It also means that if you’re using nothing but the defaults, you’re in for a world of hurt, because the default timeout-per-shutdown-phase is 30 seconds and the default terminationGracePeriodSeconds is also 30 seconds! Great, another distributed systems race of “who dies first?”.
Use Spring’s graceful shutdown setting while running in Kubernetes. Make sure timeout settings are set correctly so they do not create conflicts.
CPU Requests and Limits
Now that our application adheres to the “1-Factor app” - that is, it can be restarted gracefully, we turn our head to the important discussion of CPU requests and CPU limits. As you recall, the JVM makes a lot of assumptions based on the available CPU and memory - things like which garbage collection to use, the size of Fork/Join thread pools, and various libraries will make decisions based on the value of Runtime.getRuntime().availableProcessors().
CPU requests/limits are measured in CPU millicores. 1000 millicores translates into 1 vCPU in a virtualized environment such as the public cloud or vSphere, or a physical hyperthread if you run on bare metal. This is another plus to running Kubernetes in virtualized environments, even if you have your own hardware in a data center, because you get an additional layer of abstraction that allows you to share and over-provision resources on the same hardware.
A CPU request in Kubernetes is the minimum guaranteed amount of CPU that Kubernetes will assign to your workload.
A CPU limit measures the maximum amount of CPU that your workload can utilize before being throttled.
It’s important to note that CPU requests are not directly related to speed or performance. It may indirectly impact performance, but at its core, CPU requests are designed to help Kubernetes make better decisions on resource allocation. Nothing more.
Since CPU limits could eventually throttle your application, it could have performance implications.
Let’s review the tradeoffs when setting various CPU requests and limits combinations:
- CPU requests and limits are set to the same value: You have predictable and guaranteed CPU allocation for your pod. You might think this is exactly what you need, but if you think about how a typical Spring Boot / Java application behaves - it usually does a lot more on startup in order to create thread pools, scan for Spring beans and other startup activities. This warm-up time will greatly benefit from more CPU cores than are needed during normal operation.
- CPU requests and CPU limits are not set: Welcome to the wild west. You have zero predictability. Your pods can be killed at any point when new workloads that do have CPU requests need to allocate available capacity. Specifically for JVM workloads before JDK 19, it will actually mean that you limit each container to just a single vCPU. For workloads on JDK 19 and later, it will try to use as many vCPUs as available on the host. Please don’t use this setting.
- CPU requests are set to a value lower than the CPU limits: You get guarantees about the typical CPU consumption that your application needs, but can also burst up to the defined CPU limits during warmup time or if a sudden spike in traffic reaches your pod.
Option 3 does seem like the best of both worlds. You have guaranteed resources that will not be taken away when other resources request CPU capacity on the worker node. In fact, requests (which are based on container CPU shares) are relative. This means that they are only taken into consideration when there are constraints on the worker node from other competing resources. Otherwise, the container can use as much CPU as it needs up to the host limit, or the configured value for CPU limits. So, this begs the question: what should you set as the CPU limits?
How about No CPU Limits?
As this blog post wonderfully articulates, you really don’t get any meaningful benefits by assigning CPU limits. You’re only preventing your containers from using the excess CPU capacity that was not assigned to other containers. Why would you ever want to artificially prevent your workloads from utilizing unused CPU cycles? Perhaps it makes sense to set limits in a staging/performance environments where you want have predictable results to make decisions about production, but once you’re in production you really want to squeeze every bit of available CPU cycles as you could possibly get. Why limit yourself?
Besides, the whole mechanism that Kubernetes used to assign CPU quotas/limits is based on the amount of time you’re getting before being throttled, relative to the total number of cores on the worker node. Do you have nodes in production with different CPU capacities, or have some worker nodes with more containers compared to others? You’ll get different results on each of these worker nodes. In short - the results will be unpredictable.
Still not convinced? This set of blog posts [1] [2] [3] goes deep into the underpinnings of Kubernetes resources, and also reaches the same conclusion:
“Most of us are trying to achieve the best possible performance on the cheapest infrastructure while minimizing downtime. Production workloads should be able to utilize idle CPU. Containers won’t “steal” CPU from other containers if you set your CPU requests right, if you didn’t set CPU requests or set them badly, I’m afraid that the CPU limit wouldn’t save you.”
If that was not enough, here’s a recommendation from Tim Hockin, one of the original founders of the Kubernetes project at Google:
This is why I always advise:
- Always set memory limit == request
- Never set CPU limit
(for locally adjusted values of “always” and “never”)
— Tim Hockin (thockin.yaml) (@thockin) May 30, 2019
The important setting is the CPU requests - this will tell Kubernetes how many resources to allocate for your workload at a minimum. Setting this to too low could result in bad performance if you have a lot of other workloads on the node, and will also get you closer to the wild west scenario, since all workloads will fight for maximum resources that they should have allocated in the first place. Setting this too high could result in wasted resources and having fewer workloads running on the each node. Profile your apps before production!
Here’s a snippet of CPU configuration from the Spring Petclinic deployment:
Important note: if you’re using a fully managed Kubernetes solution such as Google Autopilot, you don’t have this level of control for your deployments. Google Autopilot specifically will set the CPU limits to the same value of the CPU requests, regardless of what you configured. This might change in the future, but the bottom line is that you don’t have as much control with these managed solutions, since they prefer predictability above all else. If you want to have complete control, use an upstream vanilla Kubernetes distribution such EKS, GKE, AKS or Tanzu Kubernetes Grid.
Things get complicated
If you think everything is good, I have some bad news - things keep changing between JDK versions and could have untrustworthy behaviour based on a combination of your JDK, your CPU requests/limits settings, and available resources.
Here’s one example: a very recent bug report in JDK 19 and later JDK-8281571 suggests not to use CPU shares to compute the JVM active processor count, and instead use the CPU limits (whaaat?!).
To understand why that is, we need to understand how Kubernetes uses assigned CPU requests, which are translated to CPU shares per container.
CPU requests are the guaranteed value. But, as briefly mentioned previously, if nothing else runs on the node, you’ll get more resources. That’s why we didn’t want to set a limit in the first place. Let’s review this with a sample 16-core worker node:
- For a single container on the node requesting 4000 millicores, the container will actually get all 16 cores because nothing else runs on the node. So, each requested core is translated to 16/4 actual cores –> 4 actual cores for each requested core.
- When a second container requesting 4000 millicores joins the node (total of 8000 millicores requested on the node), each container will now receive 8 cores. Each requested core is now translated to 16/8 actual cores –> 2 actual cores for each requested core.
- When a third container requesting 2000 millicores joins the node (total 10 cores requested on the node), the first and second containers will receive 6400 millicores each, and the third container will get 3200 millicores. Each requested core is now translated to 16/10 actual cores –> 1.6 actual cores for each requested core.
For the JDK, the CPU shares suddenly become an unreliable value. The computed value for ActiveProcessorCount will drift over time.
Houston, we have a problem.
Actually, we have two! The bug report also provides an example that shows a very problematic setting of CPU shares: 1024, which is the default setting if no CPUs were requested. While that should be translated to just 1 vCPU, it is actually being translated to (again! 🤦🏻♂️) the total number of available cores on the host machine:
This all seems like one big mess, isn’t it?
Thankfully, there’s a relatively simple solution to this: Don’t let the JVM decide the number of active processors automatically. Profile the actual usage needed for your app, and just set it yourself as part of the JAVA_TOOLS_OPTIONS parameter -XX:ActiveProcessorCount. You have the power, and the JVM will honor the setting regardless of how many actual vCPUs are given to it by the container. You can set the CPU requests to 2000 millicores, and the ActiveProcessorCount to 4 for bursting. It will work.
Set CPU requests after profiling your application. Do not set CPU limits at all. Always set the active processor count explicitly.
Memory Requests and Limits
So we have pretty good idea of what to do with CPU requests and limits. Should the same be applied to memory requests and limits?
Probably not. CPU constraints are a considered a compressed resource in Kubernetes. This means that if needed, Kubernetes can throttle your pod to make “room” for other workloads. The same cannot be said for memory. If you go past your memory limit, the container will be terminated.
Let’s review the options we have for setting memory requests and limits:
- Memory requests and limits are set to the same value: You are guaranteed the requested amount of RAM even if the worker node is low on memory.
- Memory requests is less than memory limits: If you are using more than the memory requested but less than the memory limit, and the worker node requires memory for other workloads, your pod will be terminated. Once memory is given to a pod, it cannot be taken away without restarting that pod.
- Memory request and memory limits are not set: Again, this is the wild west scenario. Pods will be terminated when a worker node is low on memory.
This one seems simpler:
For Java workloads, always set the memory requests memory limits to the same exact value.
Here’s a snippet for both the CPU and memory configuration from the Spring Petclinic deployment:
We now have a good setup for the container’s memory. But what about the JVM’s memory configuration? By default, the JVM sets the heap size to 1/4 of the available memory, which might not be the best default. What should we pass to the JAVA_TOOL_OPTIONS environment variable? Remember that your JVM lives in a container now, so your JVM memory should be a portion of the total available memory given to the container itself. The answer, as always, is that it depends. You could probably get away with setting the JVM memory to be a percentage of the container’s memory. For example, the argument -XX:MaxRAMPercentage=75.0 will set the JVM’s Max heap memory to 75% of the container’s memory, but this seems too generalized. There are different memory regions created by the JVM (Heap, Stack, DirectMemory etc.). Use something like the Java Memory Calculator mentioned in the previous section to calculate the correct values. Apply the results as an environment variable in the deployment manifest, or (if you use cloud-native buildpacks), set some values in the deployment manifest and let cloud-native buildpacks calculate the rest on startup.
Putting it all together
We now have a pretty solid understanding of what JVM arguments to pass to JAVA_TOOL_OPTIONS related to memory. Add to that the parameter for -XX:ActiveProcessorCount, and we’re in a good place.
You may also consider explicitly setting which garbage collector to use. If you set the active processor count to a single core, it will default to SerialGC. If you have 2 cores and approximately 2 GB of RAM, you’ll get ParallelGC or G1GC based on the JVM version you’re using. To avoid ambiguity, set it explicitly using -XX:+UseG1GC or -XX:-UseParallelGC, and other related arguments. If you don’t have multiple cores available for parallel garbage collection, stick to SerialGC with -XX:-UseSerialGC.
When profiling your application, consider scaling up (CPU and RAM) before scaling out. You may be surprised by the performance and even cost benefits fewer beefy containers provide compared to many small containers.
My colleague Adib Saikali has a very good summary for all of this:
Good starting points for JVM workloads: scale up before you scale out (not counting replicas used for resilience), 2000m cores and 2GB RAM, explicitly set active processor count & jvm memory settings, set cpu request but not limits, set memory requests == memory limits
— Adib Saikali (@asaikali) October 8, 2022
Spring Cloud
Spring Cloud is a popular set of components that is designed to ease the development of microservices based on Spring Boot. It began with a set of components that originally came from Open Source Netflix projects such as Eureka for service discovery and Hystrix for circuit breaking (later replaced by the Spring Cloud Circuit Breaker abstraction), and evolved over the years to include projects such as Spring Cloud Stream for event-driven applications, Spring Cloud Sleuth for distributed tracing, and Spring Cloud OpenFeign for simplified HTTP clients. While most of these Spring Cloud projects still make sense in a Kubernetes world, two of them stand out: Spring Cloud Eureka and Spring Cloud Config Server. These two solutions were developed before Kubernetes even existed, and were designed to solve two important pain points for microservices:
- How do I find other microservices in a distributed system, without having to manually manage a list of IP addresses or DNS records?
- How do I externalize my configuration to a central repository so my application can remain portable between environments?
Along with Spring Cloud Eureka, Spring Cloud Ribbon (and later Spring Cloud LoadBalancer) provided the ability call the available instances of a given microservice, based on load balancing rules such as simple round robin or advanced weighted-based routing.
Here’s a typical Spring Cloud architecture without Kubernetes:
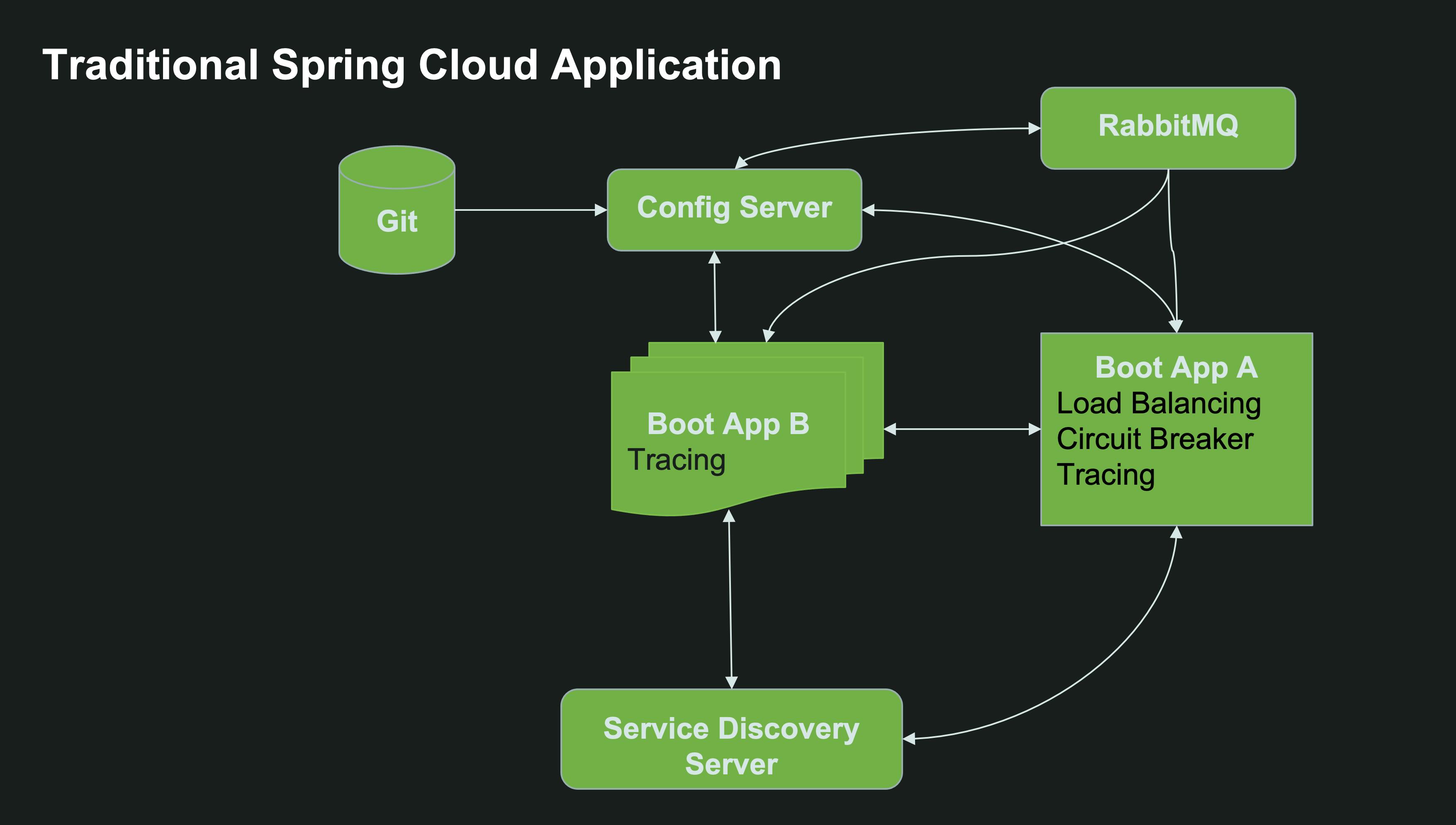
However, in Kubernetes there is already built-in solutions for service discovery and configuration management.
The built-in Kubernetes Service resource allows you to expose a set of pods/deployments behind a single internal cluster-wide IP address. It also assigns an internal DNS record to the service so it can be easily found inside the same namespace and even across namespaces in the same cluster.
For external configuration, Kubernetes provides the concept of ConfigMaps to manage a set of properties, and the notion of a Kubernetes Secret to configure sensitive data such as usernames and passwords.
If you can, prefer the Kubernetes-native solution. It will work interchangeably with other resources in the cluster written in other languages, and simplify your code since you don’t have to use Spring Cloud dependencies at all.
- For service discovery - things are rather simple: for a given Kubernetes Service
my-other-service, simply invoke the URLhttp://my-other-serviceand Kubernetes will take care of routing your Spring client application to the target server, load balancing requests based on the available number of instances. By default, you will lose the ability to perform sophisticated client-side load balancing operations such as weighted routing (unless you use Service Mesh solutions like Istio), but for the vast majority of use cases, it is more than adequate. If your service lives in another namespace, and provided you have the appropriate permissions assigned to the service account that runs your Spring application, you can make HTTP calls usinghttp://my-other-service.the-other-namespace.svc.cluster.local. - For external configuration, you can fairly easily create a ConfigMap from your existing
application.propertiesorapplication.yamland mount it to your deployment:
|
|
The result will be your application.properties or application.yaml configured as a single literal in the resulting ConfigMap:
The deployment can then be mounted to your Spring deployment manifest as follows:
|
|
In the deployment manifest above, we mounted the ConfigMap containing application.properties and also set some environment variable directly in the deployment yaml. Just because we can.
Here’s the resulting Spring Boot application with Kubernetes-native services: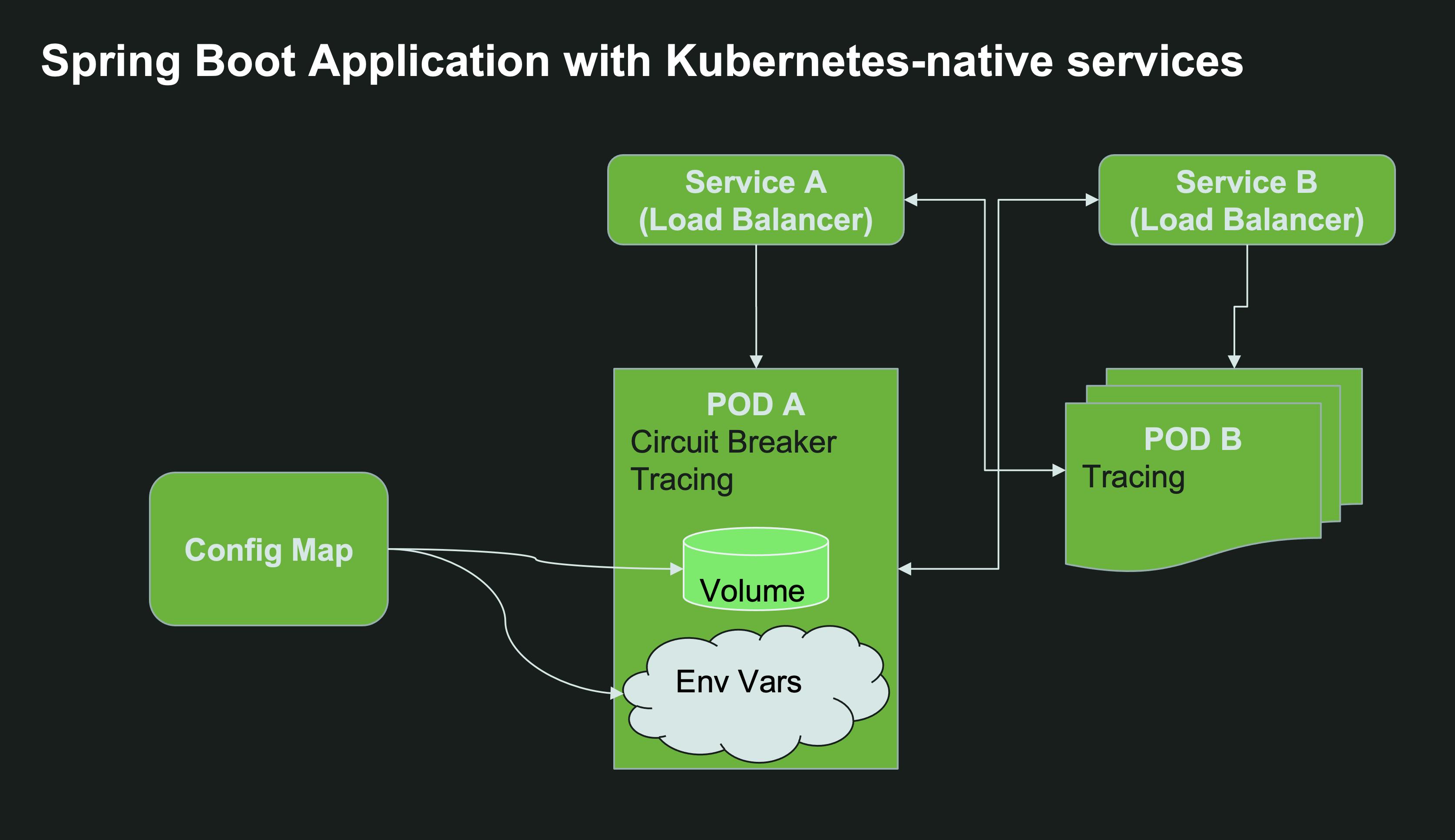
One could argue that Spring Cloud Config is better for auditing because your configuration is usually saved to a git repo which has version control and commit history, but that should also be true for your ConfigMaps and other Kubernetes resources (except secrets which should be saved in other secured storage such as Vault).
The algorithm that Spring uses to load properties from git does have more advanced logic than a simple ConfigMap. It allows for interesting topologies where generic configuration resides in a default application.properties while a microservice-specific configuration resides at a my-microservice.yaml or even my-microservice-forProfile.yaml. Still, these things are also (mostly) possible with a mix of ConfigMaps, Secrets and deployment environment variables.
You do lose one thing when you opt for Kubernetes-native Configuration: if your ConfigMap changes during runtime, the volume changes immediately but your Spring application will not get the updated values until it is restarted. With Spring Cloud Config, you had the ability to invoke POST /actuator/refresh on each of your instances, or to register for configuration change notifications using Spring Cloud Bus backed by a message broker. Both solutions would update your configuration at runtime without requiring a restart.
With Kubernetes ConfigMaps, all you can really do is restart your instances. If you have multiple instances of the application for high availability (as you should in production), you shouldn’t experience downtime. You can run a rolling restart command when a ConfigMap has changed as follows:
|
|
A rolling restart adheres to all the lifecycle phases we described above including the preStop hook and gracefulShutdown, so it could take some time to complete, but at least your application will not experience any downtime.
This all seem great for greenfield applications, but the reality is that there are a lot of applications out there that are already invested in Spring Cloud Eureka and in Spring Cloud Config. Migrating all of these brownfield applications to their Kubernetes-native counterparts could be quite the challenge, especially if your code relies heavily on annotations related to Eureka or if your git repo containing the configuration has a complex loading hierarchy.
Luckily, the Spring Cloud team has a solution for such applications, in the form of Spring Cloud Kubernetes. You can remove all references to spring-cloud-starter-config and spring-cloud-starter-netflix-eureka-server from your classpath, and replace them with the spring-cloud-kubernetes-all dependency. This dependency is a drop-in replacement that will let you easily migrate your Spring Cloud application to a Kubernetes world:
- The discovery client will now query the Kubernetes API server for available resources, instead of querying a Eureka server.
- Spring Cloud Config Client will look for attached ConfigMaps for loading the configuration, instead of relying on a Config Server.
These features are only enabled if you have the kubernetes profile configured. Luckily, when deploying a Spring boot application to Kubernetes, Spring adds this profile for you automatically.
However, there are things you should be aware of when deploying this sort of solution to production:
By default, all the instances that utilize the Spring Cloud Config Client or Spring Cloud Discovery Client will need access to the Kubernetes control plane’s API server. This means that the service account used to run the Spring pod will need permissions to access the Kubernetes control plane.
You will also need to setup a Kubernetes NetworkPolicy that allows access to the Kubernetes API Server. My colleague Stuart Charlton explains it as follows:
- The Spring Boot with the Spring Cloud Kubernetes dependency calls the Kubernetes API Server to read the ConfigMap.
- The API endpoint Spring Cloud Kubernetes uses for this is the internal service DNS for the control plane. That is to say -
kubernetes.default.svc.cluster.local. This is an internal, cluster-bound service with a custom endpoint, pointing at the Kubernetes API IP and port. - The flow is: Pod network IP –> K8s Internal Service (
kubernetes.default.svc.cluster.local) –> The K8s API Server.
So, your Kubernetes Egress CIDR block will need access to both the external API server IP and port, and potentially (depending on the Container Network Interface/CNI you have in your cluster), to the internal Kubernetes service kubernetes.default.svc.cluster.local.
This is a lot of headache infrastructure talk, isn’t it? All of these considerations now have to go into your Spring Boot workload? Seems a bit of an “infrastructure code smell”.
Luckily, the Spring team has some solutions in mind.
For the Config client part, there is a now a Kubernetes Configuration Watcher, which is essentially a service that… well “watches” the API server for ConfigMap changes based on pre-defined labels. Only this instance would require permissions and NetworkPolicy access to the API server, thus significantly reducing the policy configuration surface area. This watcher can be deployed by a Kubernetes administrator to a different namespace without the developers or the Spring Boot workload instances knowing much about the Kubernetes topology. The Config Watcher is now acting more like a standard Kubernetes operator in that regard, which is more fitting for production environments. The watcher will track all the ConfigMaps or Secrets with a particular label (spring.cloud.kubernetes.config=true or spring.cloud.kubernetes.secret=true respectively), and if any of them changes, it will call the /actuator/refresh endpoint for each one of the pods that have this ConfigMap mounted as a volume. This means you get automatic refresh of the Spring Context even over HTTP without having to resort to Spring Cloud Bus backed by a message broker - a much more simplified approach. Although, if your code already depends on Spring Cloud Bus, that option is supported as well.
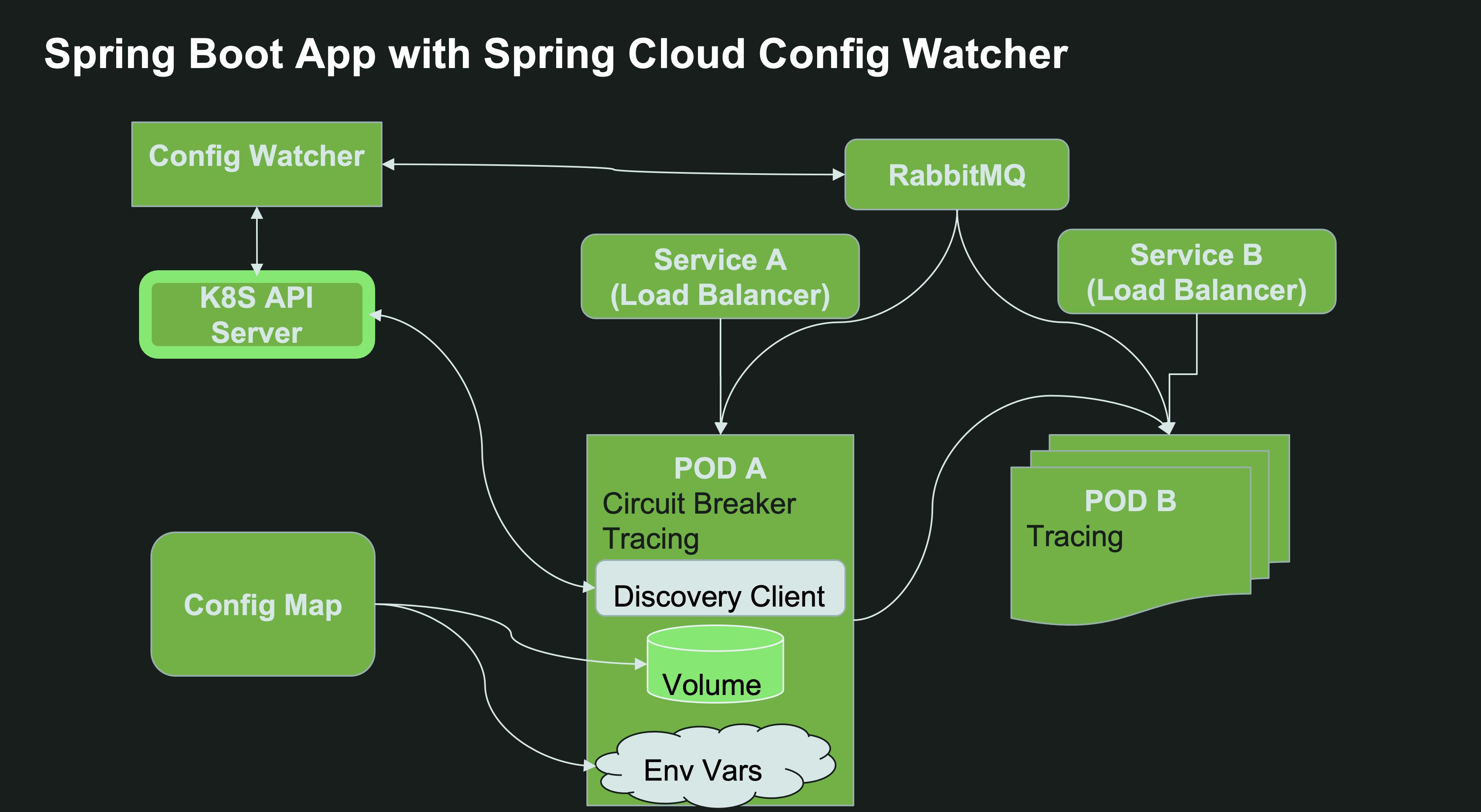
If you still want to use Spring Cloud Config Server, for example since you have a complex setup of configuration in a git repo or Vault, you can deploy a Spring Cloud Config Server to Kubernetes directly. In this use case, You will get the added benefit of being able to track both git repos and ConfigMaps/Secrets. Spring Cloud Kubernetes Config Server will also need permissions and NetworkPolicy access to the Kubernetes API server.
What about Spring Cloud Discovery Client? There’s a solution for that as well. Spring Cloud Kubernetes Discovery Server is a drop-in replacement for the Eureka API. Existing applications which use Spring Cloud Discovery Client can talk to this server as if it was Spring Cloud Eureka. Unlike Eureka though, they do not need to register themselves with this server, because Spring Cloud Kubernetes Discovery Server gets the service information on available Kubernetes services directly from the Kubernetes API server. Just like Spring Cloud Config Watcher and Spring Cloud Kubernetes Config Server, Spring Cloud Kubernetes Discovery Server requires permissions and NetworkPolicy access to the Kubernetes API server:
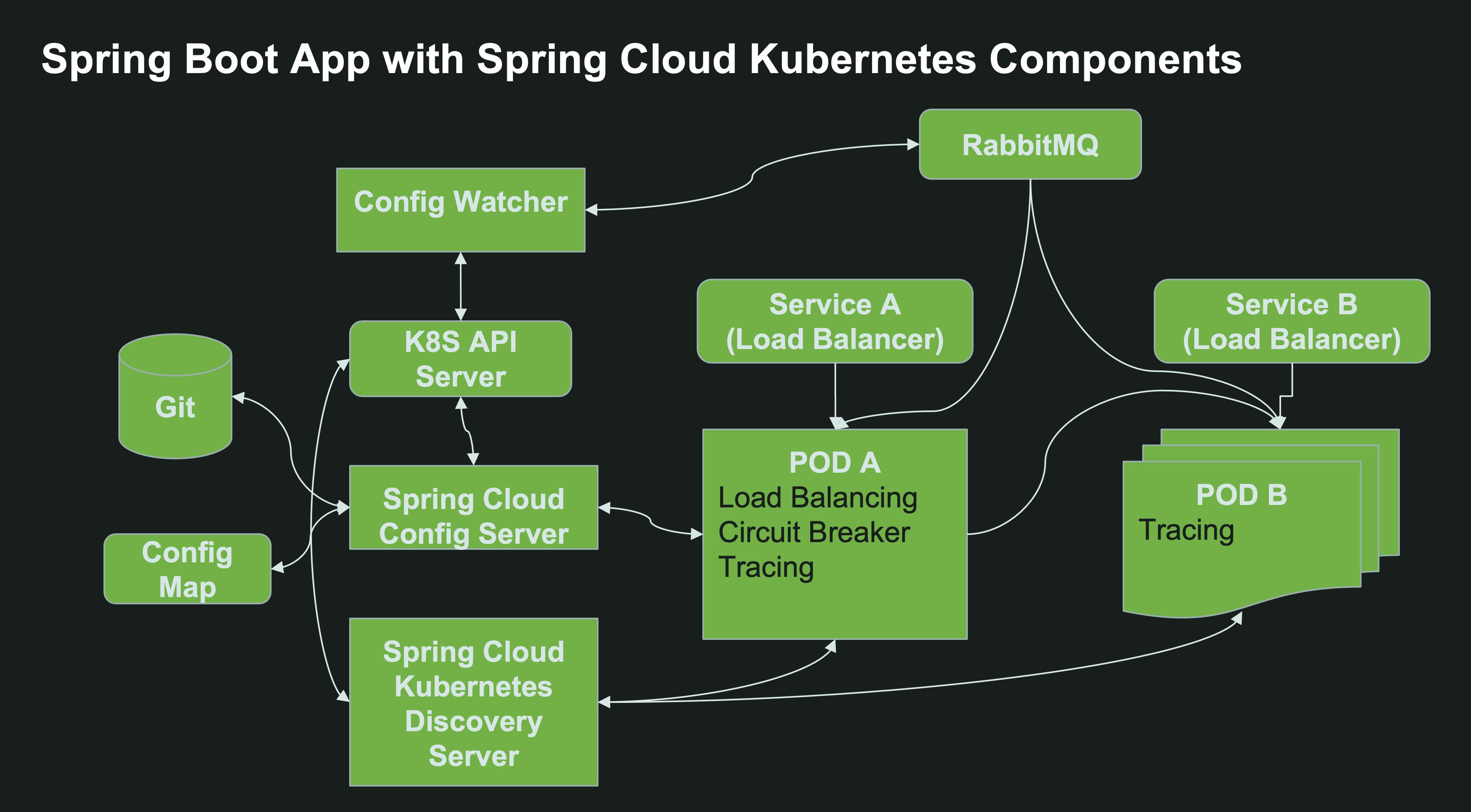
Opt for Kubernetes-native service discovery and configuration management. For brownfield applications, use Spring Cloud Kubernetes as a drop-in replacement.
Profiling your Spring Boot application
Throughout this article, I mentioned that you need to profile your application in order to better understand how to configure it for containers. Each application is different and has different requirements in terms of multi-threading and memory, and these settings have a tremendous impact on how your application will perform.
A deep dive on Spring application profiling is out of scope for this document, but here are some pointers you can use as a starting point:
-
Consider testing your app independently of the container constraints first. Just run the JVM on a relatively powerful machine with a healthy amount of CPU and Memory. To set the desired number of cores your JVM will use, set the following command (and adjust the count as needed for different performance testing):
1> java -XX:ActiveProcessorCount=4 target/spring-on-k8s.jarRemember, this setting is quite important since we don’t want to let the container “guess” the correct value. It’s best to be explicit, especially since other factors use this value for reference - such as the selected garbage collector and the size of your thread pools.
-
The JVM uses a combination of heap memory and non-heap memory. The sum of these two values will have an impact on your container configuration. In order to profile your native memory, set the following JVM arguments:
1java -XX:+UnlockDiagnosticVMOptions -XX:NativeMemoryTracking=summary -XX:+PrintNMTStatistics -jar target/myapp.jarNative memory usage can be a hidden trojan horse in your memory footprint. You could have a good ratio between heap memory and your container memory, but native memory usage could be significant based on your use case, and consume all the remaining available memory. When profiling with the arguments above, the JVM will begin tracking native memory usage in your application, and will print a usage summary when the application is stopped:
1 2 3 4 5 6 7 8 9Native Memory Tracking: Total: reserved=10376420413, committed=245521469 - Java Heap (reserved=8589934592, committed=88080384) (mmap: reserved=8589934592, committed=88080384) ... - Native Memory Tracking (reserved=3535360, committed=3535360) (malloc=6016 #84) (tracking overhead=3529344) ... -
During profiling, include the
spring-boot-starter-actuatordependency to expose production-ready endpoints that will help you have a better understanding about your application. For profiling, you’d want access to all endpoints, so set the following property during profiling, but do not keep it in production since it can pose a security risk:1management.endpoints.web.exposure.include=*If you’re monitoring with JMX, the endpoints are already exposed via the following default setting:
1management.endpoints.jmx.exposure.include=*The following endpoints will help you out with profiling:
/actuator/heapdumpwill return an hprof dump file that you can load into tools such as JProfiler, the InteliJ Profiler or others./actuator/threaddumpwill return a thread dump that you can load into tools such as Fast Thread or jstack./actuator/metricswill return metrics on the JVM that can be very useful. For example,/actuator/metrics/jvm.classes.loadedwill return the number of classes loaded by the JVM./actuator/prometheusrequires an additional dependency onmicrometer-registry-prometheus, and will expose the same metrics, but in a format that can be scraped by Prometheus and later presented in Grafana dashboards.- Online SaaS services such as DataDog or Tanzu Observability can also provide valuable input.
-
If you have the license, consider using Oracle’s Flight Recorder diagnostic and profiling tool. Spring has built-in support for Flight Recorder, by booting your Spring App (2.4 and above) with the following main method:
1 2 3 4 5 6 7 8 9@SpringBootApplication @ConfigurationPropertiesScan public class DemoApplication { public static void main(String[] args) { SpringApplication springApplication = new SpringApplication(DemoApplication.class); springApplication.setApplicationStartup(new FlightRecorderApplicationStartup()); springApplication.run(args); } }And the following JVM arguments on startup:
1java -XX:+UnlockCommercialFeatures -XX:StartFlightRecording:filename=recording.jfr,duration=10s -jar target/myapp.jarYou can instead use a BufferingApplicationStartup as follows:
1 2 3 4 5 6 7 8 9@SpringBootApplication @ConfigurationPropertiesScan public class DemoApplication { public static void main(String[] args) { SpringApplication springApplication = new SpringApplication(DemoApplication.class); springApplication.setApplicationStartup(new BufferingApplicationStartup(4096)); springApplication.run(args); } }The information collected by this solution will be exposed as a json via the actuator endpoint
/actuator/startup. -
Consider using services that offer smart code optimization and recommendations such as Github copilot. If your Spring application uses JPA and Hibernate - consider using Hypersistence Optimizer to optimize your JPA code path. Any code-level improvement means less wasted CPU cycles in production!
-
Test against “real” backing services to better simulate how your code will behave in production. In-memory databases such as H2 and HSQLDB are nice, but with tools like Testcontainers becoming so powerful, H2 and HSQLDB are just becoming technical debt since you’re testing against an emulated database when you could have tested against the real thing.
Looking further
Everything I described in this article is relevant for JVM applications at the end of 2022, with Spring Boot 2.x, which is probably the vast majority of the Spring workloads out there.
At SpringOne 2022, the Spring team will release Spring Framework 6.0 and Spring Boot 3.0. The main feature of this release is a requirement for Java 17 or later, and GA support for GraalVM with Spring Native. Spring Native compiles your Java code Ahead of Time. The Java Virtual Machine is replaced by a Substrate VM, which is specific to the target OS and architecture. Your container will require significantly less memory - probably less than 100 MB compared to 2 GB with a JVM. It also means the container starts up almost immediately - we’re now talking about milliseconds instead of seconds. This makes Spring-based applications an ideal candidate for serverless solutions such as Knative and AWS Lambda, since these solutions tend to scale to zero and need immediate response time from a cold start.
Clearly, such a meaningful change becomes a different discussion all-together, and would require revisiting most of the recommendations in this article in the future, perhaps in a separate article.
Although Spring Native shows a lot of promise, the JVM isn’t going away anytime soon. GraalVM-based solutions have tradeoffs as well:
- They boot a lot faster, but don’t achieve the same peak performance.
- You cannot use Java agents and some instrumentation solutions such as those used by some observability solutions.
- There is still work to be done in the third-party frameworks community to adapt the framework to this new architecture.
- Compilation time is longer, although it has improved considerably.
Another interesting option that could gain traction in the future is the use of JLink. This process allows you to selectively choose only the JRE modules that are required to run your application. It can greatly reduce the container size and require less runtime memory. Unlike Spring Native - this will still result in a JVM runtime, just a more lightweight version of it. As mentioned in this very old Github Issue, the focus appears to be shifting towards Spring Native, and there are no plans to focus more work on the complementary Project Jigsaw which was meant to automate the module building for frameworks such as Spring. Still, you can use JLink directly as demoed here by Dr. Dave Syer and by Adib Saikali. Compared to the images built by the Paketo Buildpacks, the JLink image can be around 40% smaller. One of the challenges for Spring is the need to still include the java.desktop module, which is a very large module and doesn’t seem right for a server-side Spring application. In Spring Framework 6.0, this module would not be needed anymore and would result in even smaller images.
A different perspective on this problem domain is Project Leyden, which was also mentioned as one of the paths forward for the Spring Framework. Leyden also aims to provide faster startup times and reduced memory footprint compared to a full-fledged JVM, using the concept of static images - basically a finite and closed version of the JVM for your specific application only. If the JDK is a Word document, Project Leyden is the PDF version of it.
Testing my own recommendations
I set myself a challenge when I began working on this article. Tanzu Application Platform is a Platform-as-a-Service that runs on any Kubernetes. You as a developer provide a simple workload yaml file containing a reference to the git repo with your source code, and in the end you have a working application in Kubernetes, powered by Knative runtime and automatic scale-to-zero. 12 lines of yaml generate thousands of lines of yaml that your team doesn’t have to maintain themselves.
Since the platform is developed by the same team that develops the Spring framework, it has production-ready defaults and best practices applied to it based on years of research and expertise. I thought it would be a good idea to compare my recommendations in this article with the resulting Knative service and pods generated by the platform. So, without further ado, here’s the a sample Kubernetes pod, created by a Knative service, which was created by Tanzu Application Platform (some lines removed for readability):
|
|
Here is a corresponding pod that was created by the above Knative service. The pod also has a Knative sidecar container which is not relevant for our use case, so I removed it for readability along with other labels and annotations:
|
|
This seems very close to the conclusions in this article. Let’s highlight the applied JAVA_TOOLS_OPTIONS parameters:
|
|
You might be wondering: “where are the memory parameters? Where is the configuration for ActiveProcessorCount”? These are applied by the Java Memory Calculator on startup. Nirvana :). Here’s the startup logs of the pod listed above. Notice the memory calculations applied:
|
|
The only thing I seemed to have missed is related to security: It’s always advisable to run your app with a service account and a non-root security context:
Conclusion
In this article, I highlighted some of the challenges and considerations that developers and Devops teams need to take in to account when deploying Spring applications to Kubernetes. There are of-course many aspects that I haven’t mentioned, so I would love to hear your feedback in the comments section. What tips can you share with the community? How can we achieve peak performance, consistency and reliability in production for our Spring workloads?
Thank you for reading.
Some content is based on “Effective Spring” by Adib Saikali. Additional feedback provided by Stuart Charlton, Dr. David Syer and Ryan Baxter.
Ref
https://odedia.org/production-considerations-for-spring-on-kubernetes