
spring batch Introduction
spring batch is a data processing framework provided by spring. Many applications in the enterprise domain require batch processing in order to perform business operations in mission-critical environments. These business operations include the following.
- Automated, complex processing of large amounts of information that can be processed most efficiently without user interaction. These operations often include time-based events (e.g., month-end calculations, notifications, or communications).
- Repetitive processing of periodic applications of complex business rules (e.g., insurance benefit determinations or rate adjustments) in very large data sets.
- Integration of information received from internal and external systems that often needs to be formatted, validated and processed into systems of record in a transactional manner. Batch processing is used to process billions of transactions per day for the enterprise.
Spring Batch is a lightweight, comprehensive batch framework designed to develop powerful batch applications critical to the day-to-day operation of enterprise systems. spring Batch builds on the expected spring framework features (productivity, POJO-based development approach, and general ease of use) while enabling developers to easily access and leverage more advanced enterprise services when necessary. Spring Batch is not a schuedling framework.
Spring Batch provides reusable features that are critical for handling large volumes of data, including logging/tracking, transaction management, job processing statistics, job restarts, skipping and resource management. It also provides more advanced technical services and features that enable extremely high volume and high performance batch jobs through optimization and partitioning techniques.
Spring Batch can be used for two simple use cases (e.g., reading files into a database or running stored procedures) and complex high-volume use cases (e.g., moving large amounts of data between databases, converting it, etc.). High-volume batch jobs can leverage the framework in a highly scalable way to process large amounts of information.
Spring Batch Architecture
A typical batch application is roughly as follows.
- Read a large number of records from a database, file, or queue.
- Process the data in some way.
- Write back the data in a modified form.
The corresponding schematic is as follows.

A general architecture of spring batch is as follows.
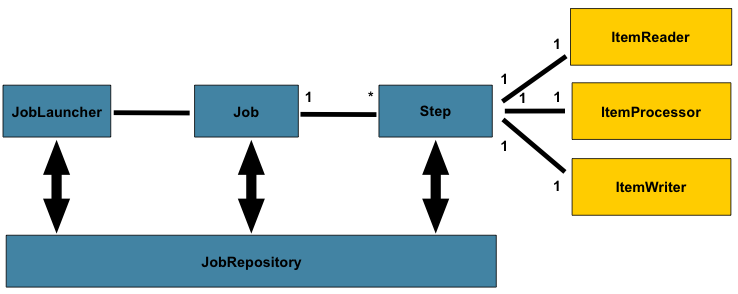
In spring batch a job can define many stepsteps, in each step you can define its own ItemReader for reading data, ItemProcesseor for processing data, ItemWriter for writing data, and each defined job is in the JobRepository inside, we can start a job through the JobLauncher.
Spring Batch Core Concepts Introduction
Here are some concepts that are core to the Spring batch framework.
What is Job
Job and Step are the two core concepts of spring batch execution of batch tasks.
Job is a concept that encapsulates the entire batch process. It is reflected in the code as a top-level interface, whose code is as follows.
|
|
There are five methods defined in the Job interface. There are two main types of jobs, one is simplejob and the other is flowjob. in spring batch, job is the top level abstraction, besides job we have JobInstance and JobExecution which are two more bottom level abstractions.
A job is the basic unit of our operation, and it consists of steps inside. A job can combine steps in a specified logical order and provides us with methods to set the same properties for all steps, such as some event listening, skipping strategies.
Spring Batch provides a default simple implementation of the Job interface in the form of the SimpleJob class, which creates some standard functionality on top of the Job. An example code using java config is as follows.
What this configuration means is that first of all, the job is given a name footballJob and then the three steps of the job are specified, which are implemented by the methods playerLoad,gameLoad, playerSummarization.
What is JobInstance
We have already mentioned JobInstance above, which is a more underlying abstraction of Job, and it is defined as follows.
His method is very simple, one is to return the id of the Job, the other is to return the name of the Job.
JobInstance refers to the concept of the job execution process in the runtime of the job (Instance is originally the meaning of the instance).
Let’s say we now have a batch job that functions to execute rows once at the end of the day. Let’s assume that the name of this batch job is EndOfDay. In this case, then there will be a logical sense of JobInstance each day , and we must record each run of the job.
What are JobParameters
As we mentioned above, if the same job is run once a day, then there is a jobIntsance every day, but their job definitions are the same, so how can we distinguish between different jobinstances of a job? Let’s make a guess, although the job definition of jobinstance is the same, but they have something different, such as the running time.
The thing provided in spring batch to identify a jobinstance is: JobParameters. The JobParameters object contains a set of parameters for starting a batch job, which can be used for identification or even as reference data during a run. Our hypothetical runtime can then be used as a JobParameters.
For example, our previous ‘EndOfDay’ job now has two instances, one generated on January 1 and the other on January 2, so we can define two JobParameter objects: one with parameters 01-01, and the other with parameters 01-02. Thus, the method to identify a JobInstance is as follows.

So, we can manipulate the correct JobInstance with the Jobparameter
What is JobExecution
JobExecution refers to the code level concept of a single attempt to run a job that we have defined. a single execution of a job may fail or succeed. Only when the execution completes successfully, the given JobInstance corresponding to the execution is also considered to be completed.
Again using the EndOfDay job described earlier as an example, suppose the first run of JobInstance for 01-01-2019 results in a failure. Then if you run the job again with the same Jobparameter parameters as the first run (i.e. 01-01-2019), a new JobExecution instance is created corresponding to the previous JobInstance, and there is still only one JobInstance.
The interface of JobExecution is defined as follows.
|
|
The annotations of each method have been explained clearly, so I won’t explain more here. Just to mention BatchStatus, JobExecution provides a method getBatchStatus to get a status of a particular execution of a job. BatchStatus is an enumeration class representing the status of a job, and is defined as follows.
These properties are critical information for a job execution and spring batch will persist them to the database. In the process of using Spring batch spring batch automatically creates some tables to store some job related information, the table used to store JobExecution is batch_job_execution, here is a screenshot of an example from the database.

What is a Step
Each Step object encapsulates a separate phase of a batch job. In fact, each Job is essentially composed of one or more steps. Each step contains all the information needed to define and control the actual batch process.
Any particular content is at the discretion of the developer writing the Job. A step can be very simple or very complex. For example, a step whose function is to load data from a file into a database would require little to no code based on the current spring batch support. More complex steps may have complex business logic that is processed as part of the process.
Like Job, Step has a StepExecution similar to JobExecution, as shown in the following figure.
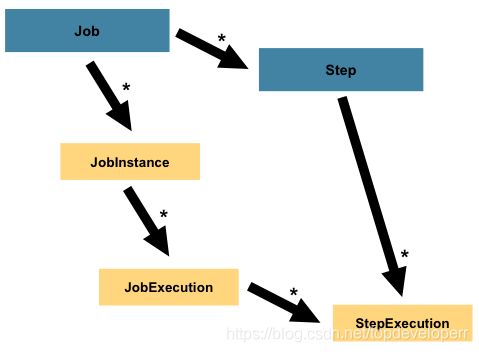
What is StepExecution
StepExecution means that a Step is executed one at a time, and a new StepExecution is created each time a Step is run, similar to a JobExecution. However, a Step may not be executed because its previous Step failed. And StepExecution is created only when the Step is actually started.
An instance of a step execution is represented by an object of class StepExecution. Each StepExecution contains a reference to its corresponding step as well as JobExecution and transaction-related data, such as commit and rollback counts and start and finish times.
In addition, each step execution contains an ExecutionContext that contains any data that the developer needs to keep in the batch run, such as statistics or status information needed for restarting. Here is an example of a screenshot from the database.

What is ExecutionContext
ExecutionContext is the execution environment for each StepExecution. It contains a series of key-value pairs. We can get the ExecutionContext with the following code.
What is JobRepository
The JobRepository is a class that is used to persist the above concepts of jobs, steps, etc. It provides CRUD operations for both Job and Step as well as the JobLauncher implementation that will be mentioned below.
The first time a Job is started, JobExecution will be retrieved from the repository, and StepExecution and JobExecution will be stored in the repository during the execution of the batch process.
The @EnableBatchProcessing annotation provides automatic configuration for the JobRepository.
What is JobLauncher
The function of JobLauncher is very simple, it is used to start the Job which has specified JobParameters, why should we emphasize the specification of JobParameter here, in fact, we have mentioned earlier, jobparameter and job together to form a job execution. Here is the code example.
The above run method implements the function of getting a JobExecution from the JobRepository and executing the Job based on the incoming Job and the jobparamaters.
What is Item Reader
ItemReader is an abstraction for reading data, its function is to provide data input for each Step. When the ItemReader finishes reading all the data, it returns null to tell subsequent operations that the data has been read.
Spring Batch provides very many useful implementation classes for ItemReader, such as JdbcPagingItemReader, JdbcCursorItemReader and so on.
The data sources supported by ItemReader are also very rich, including various types of databases, files, data streams, and so on. Almost all of our scenarios are covered.
Here is an example code of JdbcPagingItemReader.
|
|
The JdbcPagingItemReader must specify a PagingQueryProvider that is responsible for providing SQL query statements to return data by paging.
Below is an example code for JdbcCursorItemReader.
|
|
What is Item Writer
Since ItemReader is an abstraction for reading data, ItemWriter is naturally an abstraction for writing data, which is to provide data writing function for each step. The unit of writing is configurable, we can write one piece of data at a time, or write a chunk of data at a time, about the chunk will be introduced below. The ItemWriter can’t do any operation on the read data.
Spring Batch also provides a lot of useful implementation classes for ItemWriter, but of course we can also implement our own writer function.
What is Item Processor
ItemProcessor is an abstraction of the project’s business logic processing, when ItemReader reads a record before the ItemWriter writes it, we can use temProcessor to provide a function to process the business logic and manipulate the data accordingly.
If we find in ItemProcessor that a piece of data should not be written, we can indicate this by returning null. The ItemProcessor works very well with the ItemReader and ItemWriter, and the data transfer between them is very easy. We can just use them directly.
The processing flow of chunk
spring batch provides the ability for us to process data by chunk. A schematic of a chunk is as follows.
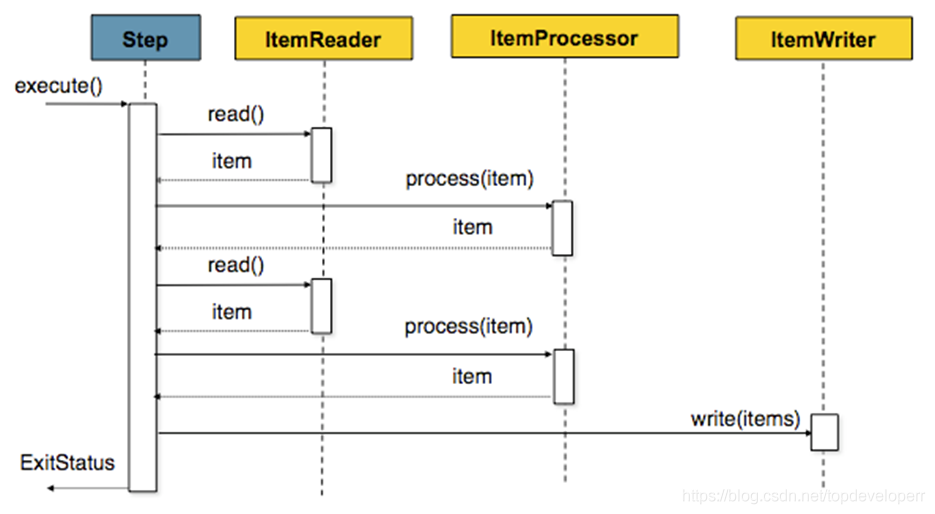
It means the same as the one shown in the diagram, because we may have many data read and write operations in one batch task, so it is not very efficient to process one by one and commit to the database, so spring batch provides the concept of chunk, we can set a chunk size, spring batch will process the data one by one, but not commit to the database, only when the number of processed data reaches the chunk size set worth, then go together to commit.
The java example definition code is as follows.

In the above step, the chunk size is set to 10, and when the number of data read by the ItemReader reaches 10, this batch of data is passed to the itemWriter together, and the transaction is committed.
skip strategy and failure handling
A batch job’s step may deal with a very large amount of data and inevitably encounter errors, which are less likely to occur, but we have to consider them because the most important thing we do is to ensure the ultimate consistency of the data. spring batch certainly takes this into account and provides us with relevant technical support. See the configuration of the bean below.

We need to pay attention to these three methods, which are skipLimit(),skip(),noSkip().
The skipLimit method means that we can set the number of exceptions we allow this step to skip, if we set it to 10, then when this step runs, as long as the number of exceptions does not exceed 10, the whole step will not fail.
Note that if skipLimit is not set, the default value is 0.
The skip method allows us to specify the exceptions that we can skip, because some of them can be ignored.
The noSkip method means that we don’t want to skip this exception, that is, to exclude this exception from all the exceptions of skip, which in the above example means to skip all the exceptions except FileNotFoundException. FileNotFoundException is a fatal exception, and when this exception is thrown, the step will fail directly.
A guide to working with batches
This section is a guide to some noteworthy points when using spring batch.
Batch Processing Principles
The following key principles and considerations should be considered when building a batch processing solution.
-
Batch architecture usually affects the architecture
-
Simplify and avoid building complex logical structures in single-batch applications whenever possible
-
Keep data processing and storage physically close to each other (in other words, keep data in the process)
-
Minimize the use of system resources, especially
I / O. Perform as many operations as possible ininternal memory. -
Look at application
I/O(analyze SQL statements) to ensure that unnecessary physicalI/Ois avoided. In particular, look for the following four common flaws.- Reading data from each transaction when it can be read once and cached or saved in working storage.
- Re-reading data from a transaction that previously read data in the same transaction.
- Causes unnecessary table or index scans.
- Failure to specify a key value in the WHERE clause of an SQL statement.
-
Do not do the same thing twice in a batch run. For example, if data aggregation is needed for reporting purposes, you should (if possible) increment the stored totals as you initially process the data, so your reporting application does not have to reprocess the same data.
-
Allocate enough memory at the beginning of the batch application to avoid time-consuming reallocations in the process.
-
Always assume the worst data integrity. Insert appropriate checks and record validation to maintain data integrity.
-
Implement checksums for internal validation whenever possible. For example, for data in a file there should be a data entry record that tells the total number of records in the file and a summary of key fields.
-
Plan and execute stress tests early in production-like environments with real data volumes.
-
In large batch task systems, data backups can be challenging, especially if the system is running at 24-7 online. Database backups are usually well handled in an online design, but file backups should be considered equally important. If the system relies on files, the file backup process should not only be in place and documented, but also tested regularly.
Disable Job from running automatically at startup
When using java config with spring batch jobs, if we don’t do any configuration, the project will run our defined batch jobs by default at startup. then how to make the project not run jobs automatically at startup?
The spring batch job will automatically run when the project starts, if we don’t want it to run at startup, we can add the following properties to application.properties.
|
|
Insufficient memory when reading data
When I was using spring batch to do data migration, I found that after the job was started, the execution was stuck at a certain point in time and the logs were no longer printed, and after waiting for some time, I got the following error.

Resource exhaustion event:the JVM was unable to allocate memory from the heap.
It means that the project reports a resource exhaustion event, telling us that the java virtual machine can no longer allocate memory for the heap.
The reason for this error is that the reader of the batch job in this project takes back all the data in the database at once and does not paginate it, which leads to insufficient memory when the amount of data is too large.
There are two solutions to this problem:
- Adjust the logic of reader to read data by paging, but it will be more troublesome to implement and the operation efficiency will be reduced.
- Increase the service memory
Reference https://blog.csdn.net/topdeveloperr/article/details/84337956